具有 LayerScale 的類別注意力圖像轉換器
作者: Sayak Paul
建立日期 2022/09/19
上次修改日期 2022/11/21
描述: 實作配備類別注意力與 LayerScale 的圖像轉換器。

簡介
在本教學中,我們實作由 Touvron 等人於使用圖像轉換器進行更深入的研究中提出的 CaiT(圖像轉換器中的類別注意力)。深度縮放,即增加模型深度以獲得更好的效能和泛化能力,對於卷積神經網路而言相當成功(例如,Tan 等人、Dollár 等人)。但是,將相同的模型縮放原則應用於視覺轉換器(Dosovitskiy 等人)的效果並不理想 – 它們的效能在深度縮放下很快就會飽和。請注意,這裡的一個假設是,在執行模型縮放時,底層預訓練數據集始終保持不變。
在 CaiT 論文中,作者研究了這種現象,並提出了對 vanilla ViT(視覺轉換器)架構的修改,以減輕這個問題。
本教學的結構如下:
- CaiT 個別區塊的實作
- 整理所有區塊以建立 CaiT 模型
- 載入預訓練的 CaiT 模型
- 取得預測結果
- CaiT 不同注意力層的可視化
讀者應已熟悉視覺轉換器。以下是 Keras 中視覺轉換器的實作:使用視覺轉換器進行影像分類。
導入
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import io
import typing
from urllib.request import urlopen
import matplotlib.pyplot as plt
import numpy as np
import PIL
import keras
from keras import layers
from keras import ops
LayerScale 層
我們先實作 LayerScale 層,這是 CaiT 論文中提出的兩個修改之一。
當增加 ViT 模型的深度時,它們會遇到最佳化不穩定性,最終不會收斂。每個轉換器區塊內的殘差連接會引入資訊瓶頸。當深度增加時,這個瓶頸會迅速爆炸並偏離底層模型的最佳化路徑。
以下方程式表示在轉換器區塊內新增殘差連接的位置

其中,SA 代表自我注意力,FFN 代表前饋網路,而 eta 表示 LayerNorm 運算子(Ba 等人)。
LayerScale 的正式實作如下:

其中,lambda 是可學習的參數,並以非常小的值 ({0.1, 1e-5, 1e-6}) 初始化。diag 代表對角矩陣。
直觀來說,LayerScale 有助於控制殘差分支的貢獻。LayerScale 的可學習參數初始化為一個小值,讓分支像恆等函數一樣運作,然後讓它們在訓練期間找出互動的程度。對角矩陣額外有助於控制殘差輸入各個維度的貢獻,因為它是按每個通道應用的。
LayerScale 的實際實作比聽起來簡單。
class LayerScale(layers.Layer):
"""LayerScale as introduced in CaiT: https://arxiv.org/abs/2103.17239.
Args:
init_values (float): value to initialize the diagonal matrix of LayerScale.
projection_dim (int): projection dimension used in LayerScale.
"""
def __init__(self, init_values: float, projection_dim: int, **kwargs):
super().__init__(**kwargs)
self.gamma = self.add_weight(
shape=(projection_dim,),
initializer=keras.initializers.Constant(init_values),
)
def call(self, x, training=False):
return x * self.gamma
隨機深度層
自從引入以來(Huang 等人),隨機深度已成為幾乎所有現代神經網路架構中受歡迎的元件。CaiT 也不例外。討論隨機深度超出本筆記本的範圍。如果需要複習,您可以參考這個資源。
class StochasticDepth(layers.Layer):
"""Stochastic Depth layer (https://arxiv.org/abs/1603.09382).
Reference:
https://github.com/rwightman/pytorch-image-models
"""
def __init__(self, drop_prob: float, **kwargs):
super().__init__(**kwargs)
self.drop_prob = drop_prob
self.seed_generator = keras.random.SeedGenerator(1337)
def call(self, x, training=False):
if training:
keep_prob = 1 - self.drop_prob
shape = (ops.shape(x)[0],) + (1,) * (len(x.shape) - 1)
random_tensor = keep_prob + ops.random.uniform(
shape, minval=0, maxval=1, seed=self.seed_generator
)
random_tensor = ops.floor(random_tensor)
return (x / keep_prob) * random_tensor
return x
類別注意力
vanilla ViT 使用自我注意力 (SA) 層來模擬圖像圖塊和可學習的 CLS 標記如何相互互動。CaiT 作者建議將負責關注圖像圖塊和 CLS 標記的注意力層分開。
當使用 ViT 進行任何判別任務(例如分類)時,我們通常會取得屬於 CLS 標記的表示,然後將它們傳遞到特定於任務的標頭。這與使用通常在卷積神經網路中使用的全域平均池化相反。
CLS 標記和其他圖像圖塊之間的互動會透過自我注意力層均勻處理。正如 CaiT 作者指出的那樣,這種設定具有糾纏不清的效果。一方面,自我注意力層負責模擬圖像圖塊。另一方面,它們也負責透過 CLS 標記總結模擬的資訊,使其對學習目標有用。
為了幫助解開這兩件事,作者建議:
- 在網路的較後階段引入 CLS 標記。
- 透過一組單獨的注意力層來建模 CLS 標記和與圖像圖塊相關的表示之間的互動。作者將此稱為類別注意力 (CA)。
下圖(取自原始論文)描繪了這個概念

這是透過將 CLS 標記嵌入視為 CA 層中的查詢來實現的。 CLS 標記嵌入和圖像塊嵌入會作為鍵和值輸入。
請注意,此處「嵌入 (embeddings)」和「表示 (representations)」已交替使用。
class ClassAttention(layers.Layer):
"""Class attention as proposed in CaiT: https://arxiv.org/abs/2103.17239.
Args:
projection_dim (int): projection dimension for the query, key, and value
of attention.
num_heads (int): number of attention heads.
dropout_rate (float): dropout rate to be used for dropout in the attention
scores as well as the final projected outputs.
"""
def __init__(
self, projection_dim: int, num_heads: int, dropout_rate: float, **kwargs
):
super().__init__(**kwargs)
self.num_heads = num_heads
head_dim = projection_dim // num_heads
self.scale = head_dim**-0.5
self.q = layers.Dense(projection_dim)
self.k = layers.Dense(projection_dim)
self.v = layers.Dense(projection_dim)
self.attn_drop = layers.Dropout(dropout_rate)
self.proj = layers.Dense(projection_dim)
self.proj_drop = layers.Dropout(dropout_rate)
def call(self, x, training=False):
batch_size, num_patches, num_channels = (
ops.shape(x)[0],
ops.shape(x)[1],
ops.shape(x)[2],
)
# Query projection. `cls_token` embeddings are queries.
q = ops.expand_dims(self.q(x[:, 0]), axis=1)
q = ops.reshape(
q, (batch_size, 1, self.num_heads, num_channels // self.num_heads)
) # Shape: (batch_size, 1, num_heads, dimension_per_head)
q = ops.transpose(q, axes=[0, 2, 1, 3])
scale = ops.cast(self.scale, dtype=q.dtype)
q = q * scale
# Key projection. Patch embeddings as well the cls embedding are used as keys.
k = self.k(x)
k = ops.reshape(
k, (batch_size, num_patches, self.num_heads, num_channels // self.num_heads)
) # Shape: (batch_size, num_tokens, num_heads, dimension_per_head)
k = ops.transpose(k, axes=[0, 2, 3, 1])
# Value projection. Patch embeddings as well the cls embedding are used as values.
v = self.v(x)
v = ops.reshape(
v, (batch_size, num_patches, self.num_heads, num_channels // self.num_heads)
)
v = ops.transpose(v, axes=[0, 2, 1, 3])
# Calculate attention scores between cls_token embedding and patch embeddings.
attn = ops.matmul(q, k)
attn = ops.nn.softmax(attn, axis=-1)
attn = self.attn_drop(attn, training=training)
x_cls = ops.matmul(attn, v)
x_cls = ops.transpose(x_cls, axes=[0, 2, 1, 3])
x_cls = ops.reshape(x_cls, (batch_size, 1, num_channels))
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls, training=training)
return x_cls, attn
談話頭注意力機制 (Talking Head Attention)
CaiT 的作者使用談話頭注意力機制(Shazeer 等人)而不是原始 Transformer 論文(Vaswani 等人)中使用的標準縮放點積多頭注意力機制。他們在 softmax 運算之前和之後引入了兩個線性投影,以獲得更好的結果。
若要更嚴謹地探討談話頭注意力機制和標準注意力機制,請參閱各自的論文(連結如上)。
class TalkingHeadAttention(layers.Layer):
"""Talking-head attention as proposed in CaiT: https://arxiv.org/abs/2003.02436.
Args:
projection_dim (int): projection dimension for the query, key, and value
of attention.
num_heads (int): number of attention heads.
dropout_rate (float): dropout rate to be used for dropout in the attention
scores as well as the final projected outputs.
"""
def __init__(
self, projection_dim: int, num_heads: int, dropout_rate: float, **kwargs
):
super().__init__(**kwargs)
self.num_heads = num_heads
head_dim = projection_dim // self.num_heads
self.scale = head_dim**-0.5
self.qkv = layers.Dense(projection_dim * 3)
self.attn_drop = layers.Dropout(dropout_rate)
self.proj = layers.Dense(projection_dim)
self.proj_l = layers.Dense(self.num_heads)
self.proj_w = layers.Dense(self.num_heads)
self.proj_drop = layers.Dropout(dropout_rate)
def call(self, x, training=False):
B, N, C = ops.shape(x)[0], ops.shape(x)[1], ops.shape(x)[2]
# Project the inputs all at once.
qkv = self.qkv(x)
# Reshape the projected output so that they're segregated in terms of
# query, key, and value projections.
qkv = ops.reshape(qkv, (B, N, 3, self.num_heads, C // self.num_heads))
# Transpose so that the `num_heads` becomes the leading dimensions.
# Helps to better segregate the representation sub-spaces.
qkv = ops.transpose(qkv, axes=[2, 0, 3, 1, 4])
scale = ops.cast(self.scale, dtype=qkv.dtype)
q, k, v = qkv[0] * scale, qkv[1], qkv[2]
# Obtain the raw attention scores.
attn = ops.matmul(q, ops.transpose(k, axes=[0, 1, 3, 2]))
# Linear projection of the similarities between the query and key projections.
attn = self.proj_l(ops.transpose(attn, axes=[0, 2, 3, 1]))
# Normalize the attention scores.
attn = ops.transpose(attn, axes=[0, 3, 1, 2])
attn = ops.nn.softmax(attn, axis=-1)
# Linear projection on the softmaxed scores.
attn = self.proj_w(ops.transpose(attn, axes=[0, 2, 3, 1]))
attn = ops.transpose(attn, axes=[0, 3, 1, 2])
attn = self.attn_drop(attn, training=training)
# Final set of projections as done in the vanilla attention mechanism.
x = ops.matmul(attn, v)
x = ops.transpose(x, axes=[0, 2, 1, 3])
x = ops.reshape(x, (B, N, C))
x = self.proj(x)
x = self.proj_drop(x, training=training)
return x, attn
前饋網路 (Feed-forward Network)
接下來,我們實作前饋網路,它是 Transformer 區塊中的其中一個組件。
def mlp(x, dropout_rate: float, hidden_units: typing.List[int]):
"""FFN for a Transformer block."""
for idx, units in enumerate(hidden_units):
x = layers.Dense(
units,
activation=ops.nn.gelu if idx == 0 else None,
bias_initializer=keras.initializers.RandomNormal(stddev=1e-6),
)(x)
x = layers.Dropout(dropout_rate)(x)
return x
其他區塊
在接下來的兩個儲存格中,我們將剩餘的區塊實作為獨立函式
LayerScaleBlockClassAttention(),它會傳回一個keras.Model。它是一個配備類別注意力、LayerScale 和隨機深度的 Transformer 區塊。它會對 CLS 嵌入和圖像塊嵌入進行操作。LayerScaleBlock(),它會傳回一個keras.model。它也是一個只對圖像塊嵌入進行操作的 Transformer 區塊。它配備了 LayerScale 和隨機深度。
def LayerScaleBlockClassAttention(
projection_dim: int,
num_heads: int,
layer_norm_eps: float,
init_values: float,
mlp_units: typing.List[int],
dropout_rate: float,
sd_prob: float,
name: str,
):
"""Pre-norm transformer block meant to be applied to the embeddings of the
cls token and the embeddings of image patches.
Includes LayerScale and Stochastic Depth.
Args:
projection_dim (int): projection dimension to be used in the
Transformer blocks and patch projection layer.
num_heads (int): number of attention heads.
layer_norm_eps (float): epsilon to be used for Layer Normalization.
init_values (float): initial value for the diagonal matrix used in LayerScale.
mlp_units (List[int]): dimensions of the feed-forward network used in
the Transformer blocks.
dropout_rate (float): dropout rate to be used for dropout in the attention
scores as well as the final projected outputs.
sd_prob (float): stochastic depth rate.
name (str): a name identifier for the block.
Returns:
A keras.Model instance.
"""
x = keras.Input((None, projection_dim))
x_cls = keras.Input((None, projection_dim))
inputs = keras.layers.Concatenate(axis=1)([x_cls, x])
# Class attention (CA).
x1 = layers.LayerNormalization(epsilon=layer_norm_eps)(inputs)
attn_output, attn_scores = ClassAttention(projection_dim, num_heads, dropout_rate)(
x1
)
attn_output = (
LayerScale(init_values, projection_dim)(attn_output)
if init_values
else attn_output
)
attn_output = StochasticDepth(sd_prob)(attn_output) if sd_prob else attn_output
x2 = keras.layers.Add()([x_cls, attn_output])
# FFN.
x3 = layers.LayerNormalization(epsilon=layer_norm_eps)(x2)
x4 = mlp(x3, hidden_units=mlp_units, dropout_rate=dropout_rate)
x4 = LayerScale(init_values, projection_dim)(x4) if init_values else x4
x4 = StochasticDepth(sd_prob)(x4) if sd_prob else x4
outputs = keras.layers.Add()([x2, x4])
return keras.Model([x, x_cls], [outputs, attn_scores], name=name)
def LayerScaleBlock(
projection_dim: int,
num_heads: int,
layer_norm_eps: float,
init_values: float,
mlp_units: typing.List[int],
dropout_rate: float,
sd_prob: float,
name: str,
):
"""Pre-norm transformer block meant to be applied to the embeddings of the
image patches.
Includes LayerScale and Stochastic Depth.
Args:
projection_dim (int): projection dimension to be used in the
Transformer blocks and patch projection layer.
num_heads (int): number of attention heads.
layer_norm_eps (float): epsilon to be used for Layer Normalization.
init_values (float): initial value for the diagonal matrix used in LayerScale.
mlp_units (List[int]): dimensions of the feed-forward network used in
the Transformer blocks.
dropout_rate (float): dropout rate to be used for dropout in the attention
scores as well as the final projected outputs.
sd_prob (float): stochastic depth rate.
name (str): a name identifier for the block.
Returns:
A keras.Model instance.
"""
encoded_patches = keras.Input((None, projection_dim))
# Self-attention.
x1 = layers.LayerNormalization(epsilon=layer_norm_eps)(encoded_patches)
attn_output, attn_scores = TalkingHeadAttention(
projection_dim, num_heads, dropout_rate
)(x1)
attn_output = (
LayerScale(init_values, projection_dim)(attn_output)
if init_values
else attn_output
)
attn_output = StochasticDepth(sd_prob)(attn_output) if sd_prob else attn_output
x2 = layers.Add()([encoded_patches, attn_output])
# FFN.
x3 = layers.LayerNormalization(epsilon=layer_norm_eps)(x2)
x4 = mlp(x3, hidden_units=mlp_units, dropout_rate=dropout_rate)
x4 = LayerScale(init_values, projection_dim)(x4) if init_values else x4
x4 = StochasticDepth(sd_prob)(x4) if sd_prob else x4
outputs = layers.Add()([x2, x4])
return keras.Model(encoded_patches, [outputs, attn_scores], name=name)
有了這些區塊,我們現在可以將它們整理成最終的 CaiT 模型。
整合各個部分:CaiT 模型
class CaiT(keras.Model):
"""CaiT model.
Args:
projection_dim (int): projection dimension to be used in the
Transformer blocks and patch projection layer.
patch_size (int): patch size of the input images.
num_patches (int): number of patches after extracting the image patches.
init_values (float): initial value for the diagonal matrix used in LayerScale.
mlp_units: (List[int]): dimensions of the feed-forward network used in
the Transformer blocks.
sa_ffn_layers (int): number of self-attention Transformer blocks.
ca_ffn_layers (int): number of class-attention Transformer blocks.
num_heads (int): number of attention heads.
layer_norm_eps (float): epsilon to be used for Layer Normalization.
dropout_rate (float): dropout rate to be used for dropout in the attention
scores as well as the final projected outputs.
sd_prob (float): stochastic depth rate.
global_pool (str): denotes how to pool the representations coming out of
the final Transformer block.
pre_logits (bool): if set to True then don't add a classification head.
num_classes (int): number of classes to construct the final classification
layer with.
"""
def __init__(
self,
projection_dim: int,
patch_size: int,
num_patches: int,
init_values: float,
mlp_units: typing.List[int],
sa_ffn_layers: int,
ca_ffn_layers: int,
num_heads: int,
layer_norm_eps: float,
dropout_rate: float,
sd_prob: float,
global_pool: str,
pre_logits: bool,
num_classes: int,
**kwargs,
):
if global_pool not in ["token", "avg"]:
raise ValueError(
'Invalid value received for `global_pool`, should be either `"token"` or `"avg"`.'
)
super().__init__(**kwargs)
# Responsible for patchifying the input images and the linearly projecting them.
self.projection = keras.Sequential(
[
layers.Conv2D(
filters=projection_dim,
kernel_size=(patch_size, patch_size),
strides=(patch_size, patch_size),
padding="VALID",
name="conv_projection",
kernel_initializer="lecun_normal",
),
layers.Reshape(
target_shape=(-1, projection_dim),
name="flatten_projection",
),
],
name="projection",
)
# CLS token and the positional embeddings.
self.cls_token = self.add_weight(
shape=(1, 1, projection_dim), initializer="zeros"
)
self.pos_embed = self.add_weight(
shape=(1, num_patches, projection_dim), initializer="zeros"
)
# Projection dropout.
self.pos_drop = layers.Dropout(dropout_rate, name="projection_dropout")
# Stochastic depth schedule.
dpr = [sd_prob for _ in range(sa_ffn_layers)]
# Self-attention (SA) Transformer blocks operating only on the image patch
# embeddings.
self.blocks = [
LayerScaleBlock(
projection_dim=projection_dim,
num_heads=num_heads,
layer_norm_eps=layer_norm_eps,
init_values=init_values,
mlp_units=mlp_units,
dropout_rate=dropout_rate,
sd_prob=dpr[i],
name=f"sa_ffn_block_{i}",
)
for i in range(sa_ffn_layers)
]
# Class Attention (CA) Transformer blocks operating on the CLS token and image patch
# embeddings.
self.blocks_token_only = [
LayerScaleBlockClassAttention(
projection_dim=projection_dim,
num_heads=num_heads,
layer_norm_eps=layer_norm_eps,
init_values=init_values,
mlp_units=mlp_units,
dropout_rate=dropout_rate,
name=f"ca_ffn_block_{i}",
sd_prob=0.0, # No Stochastic Depth in the class attention layers.
)
for i in range(ca_ffn_layers)
]
# Pre-classification layer normalization.
self.norm = layers.LayerNormalization(epsilon=layer_norm_eps, name="head_norm")
# Representation pooling for classification head.
self.global_pool = global_pool
# Classification head.
self.pre_logits = pre_logits
self.num_classes = num_classes
if not pre_logits:
self.head = layers.Dense(num_classes, name="classification_head")
def call(self, x, training=False):
# Notice how CLS token is not added here.
x = self.projection(x)
x = x + self.pos_embed
x = self.pos_drop(x)
# SA+FFN layers.
sa_ffn_attn = {}
for blk in self.blocks:
x, attn_scores = blk(x)
sa_ffn_attn[f"{blk.name}_att"] = attn_scores
# CA+FFN layers.
ca_ffn_attn = {}
cls_tokens = ops.tile(self.cls_token, (ops.shape(x)[0], 1, 1))
for blk in self.blocks_token_only:
cls_tokens, attn_scores = blk([x, cls_tokens])
ca_ffn_attn[f"{blk.name}_att"] = attn_scores
x = ops.concatenate([cls_tokens, x], axis=1)
x = self.norm(x)
# Always return the attention scores from the SA+FFN and CA+FFN layers
# for convenience.
if self.global_pool:
x = (
ops.reduce_mean(x[:, 1:], axis=1)
if self.global_pool == "avg"
else x[:, 0]
)
return (
(x, sa_ffn_attn, ca_ffn_attn)
if self.pre_logits
else (self.head(x), sa_ffn_attn, ca_ffn_attn)
)
以這種方式分離 SA 和 CA 層有助於模型更具體地專注於底層目標
- 圖像塊之間的模型相依性
- 總結圖像塊中的資訊,以用於手邊任務的 CLS 標記
現在我們已經定義了 CaiT 模型,是時候進行測試了。我們將首先定義一個模型設定,它將傳遞給我們的 CaiT 類別以進行初始化。
定義模型設定
def get_config(
image_size: int = 224,
patch_size: int = 16,
projection_dim: int = 192,
sa_ffn_layers: int = 24,
ca_ffn_layers: int = 2,
num_heads: int = 4,
mlp_ratio: int = 4,
layer_norm_eps=1e-6,
init_values: float = 1e-5,
dropout_rate: float = 0.0,
sd_prob: float = 0.0,
global_pool: str = "token",
pre_logits: bool = False,
num_classes: int = 1000,
) -> typing.Dict:
"""Default configuration for CaiT models (cait_xxs24_224).
Reference:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/cait.py
"""
config = {}
# Patchification and projection.
config["patch_size"] = patch_size
config["num_patches"] = (image_size // patch_size) ** 2
# LayerScale.
config["init_values"] = init_values
# Dropout and Stochastic Depth.
config["dropout_rate"] = dropout_rate
config["sd_prob"] = sd_prob
# Shared across different blocks and layers.
config["layer_norm_eps"] = layer_norm_eps
config["projection_dim"] = projection_dim
config["mlp_units"] = [
projection_dim * mlp_ratio,
projection_dim,
]
# Attention layers.
config["num_heads"] = num_heads
config["sa_ffn_layers"] = sa_ffn_layers
config["ca_ffn_layers"] = ca_ffn_layers
# Representation pooling and task specific parameters.
config["global_pool"] = global_pool
config["pre_logits"] = pre_logits
config["num_classes"] = num_classes
return config
如果您已經了解 ViT 架構,則大多數設定變數應該會讓您感到熟悉。重點放在 sa_ffn_layers 和 ca_ffn_layers 上,它們控制著 SA-Transformer 區塊和 CA-Transformer 區塊的數量。您可以輕鬆修改此 get_config() 方法,為您自己的資料集例項化 CaiT 模型。
模型例項化
image_size = 224
num_channels = 3
batch_size = 2
config = get_config()
cait_xxs24_224 = CaiT(**config)
dummy_inputs = ops.ones((batch_size, image_size, image_size, num_channels))
_ = cait_xxs24_224(dummy_inputs)
我們可以成功地使用該模型執行推論。但是,實作正確性如何呢?有很多方法可以驗證它
- 取得模型在 ImageNet-1k 驗證集上的效能(假設它已使用預先訓練的參數填入)(因為預先訓練的資料集為 ImageNet-1k)。
- 在不同的資料集上微調模型。
為了驗證這一點,我們將載入同一個模型的另一個例項,該例項已經使用預先訓練的參數填入。請參閱 此儲存庫(由本筆記本的作者開發)以取得更多詳細資訊。此外,該儲存庫還提供了程式碼,用於驗證模型在 ImageNet-1k 驗證集和 微調上的效能。
載入預先訓練的模型
model_gcs_path = "gs://kaggle-tfhub-models-uncompressed/tfhub-modules/sayakpaul/cait_xxs24_224/1/uncompressed"
pretrained_model = keras.Sequential(
[keras.layers.TFSMLayer(model_gcs_path, call_endpoint="serving_default")]
)
推論公用程式
在接下來的幾個儲存格中,我們開發了使用預先訓練的模型執行推論所需的預處理公用程式。
# The preprocessing transformations include center cropping, and normalizing
# the pixel values with the ImageNet-1k training stats (mean and standard deviation).
crop_layer = keras.layers.CenterCrop(image_size, image_size)
norm_layer = keras.layers.Normalization(
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
variance=[(0.229 * 255) ** 2, (0.224 * 255) ** 2, (0.225 * 255) ** 2],
)
def preprocess_image(image, size=image_size):
image = np.array(image)
image_resized = ops.expand_dims(image, 0)
resize_size = int((256 / image_size) * size)
image_resized = ops.image.resize(
image_resized, (resize_size, resize_size), interpolation="bicubic"
)
image_resized = crop_layer(image_resized)
return norm_layer(image_resized).numpy()
def load_image_from_url(url):
image_bytes = io.BytesIO(urlopen(url).read())
image = PIL.Image.open(image_bytes)
preprocessed_image = preprocess_image(image)
return image, preprocessed_image
現在,我們擷取 ImageNet-1k 標籤並將其載入,因為我們載入的模型是在 ImageNet-1k 資料集上預先訓練的。
# ImageNet-1k class labels.
imagenet_labels = (
"https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt"
)
label_path = keras.utils.get_file(origin=imagenet_labels)
with open(label_path, "r") as f:
lines = f.readlines()
imagenet_labels = [line.rstrip() for line in lines]
載入圖片
img_url = "https://i.imgur.com/ErgfLTn.jpg"
image, preprocessed_image = load_image_from_url(img_url)
# https://unsplash.com/photos/Ho93gVTRWW8
plt.imshow(image)
plt.axis("off")
plt.show()

取得預測
outputs = pretrained_model.predict(preprocessed_image)
logits = outputs["output_1"]
ca_ffn_block_0_att = outputs["output_3_ca_ffn_block_0_att"]
ca_ffn_block_1_att = outputs["output_3_ca_ffn_block_1_att"]
predicted_label = imagenet_labels[int(np.argmax(logits))]
print(predicted_label)
1/1 ━━━━━━━━━━━━━━━━━━━━ 30s 30s/step
monarch, monarch_butterfly, milkweed_butterfly, Danaus_plexippus
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1700601113.319904 361514 device_compiler.h:187] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
既然我們已經取得了預測(似乎符合預期),我們可以進一步擴展我們的研究。按照 CaiT 作者的說法,我們可以調查注意力層的注意力分數。這有助於我們更深入地了解 CaiT 論文中引入的修改。
視覺化注意力層
我們首先檢查類別注意力層傳回的注意力權重的形狀。
# (batch_size, nb_attention_heads, num_cls_token, seq_length)
print("Shape of the attention scores from a class attention block:")
print(ca_ffn_block_0_att.shape)
Shape of the attention scores from a class attention block:
(1, 4, 1, 197)
該形狀表示我們已獲得每個個別注意力頭的注意力權重。它們量化了 CLS 標記與自身和其餘圖像塊相關的資訊。
接下來,我們編寫一個公用程式來
- 視覺化類別注意力層中個別注意力頭所關注的內容。這有助於我們了解 CaiT 模型中如何產生空間類別關係。
- 從第一個類別注意力層取得顯著圖,這有助於了解 CA 層如何彙總影像中感興趣區域的資訊。
此公用程式參照自原始 CaiT 論文的圖 6 和圖 7。這也是 此筆記本(由本教學的作者開發)的一部分。
# Reference:
# https://github.com/facebookresearch/dino/blob/main/visualize_attention.py
patch_size = 16
def get_cls_attention_map(
attention_scores,
return_saliency=False,
) -> np.ndarray:
"""
Returns attention scores from a particular attention block.
Args:
attention_scores: the attention scores from the attention block to
visualize.
return_saliency: a boolean flag if set to True also returns the salient
representations of the attention block.
"""
w_featmap = preprocessed_image.shape[2] // patch_size
h_featmap = preprocessed_image.shape[1] // patch_size
nh = attention_scores.shape[1] # Number of attention heads.
# Taking the representations from CLS token.
attentions = attention_scores[0, :, 0, 1:].reshape(nh, -1)
# Reshape the attention scores to resemble mini patches.
attentions = attentions.reshape(nh, w_featmap, h_featmap)
if not return_saliency:
attentions = attentions.transpose((1, 2, 0))
else:
attentions = np.mean(attentions, axis=0)
attentions = (attentions - attentions.min()) / (
attentions.max() - attentions.min()
)
attentions = np.expand_dims(attentions, -1)
# Resize the attention patches to 224x224 (224: 14x16)
attentions = ops.image.resize(
attentions,
size=(h_featmap * patch_size, w_featmap * patch_size),
interpolation="bicubic",
)
return attentions
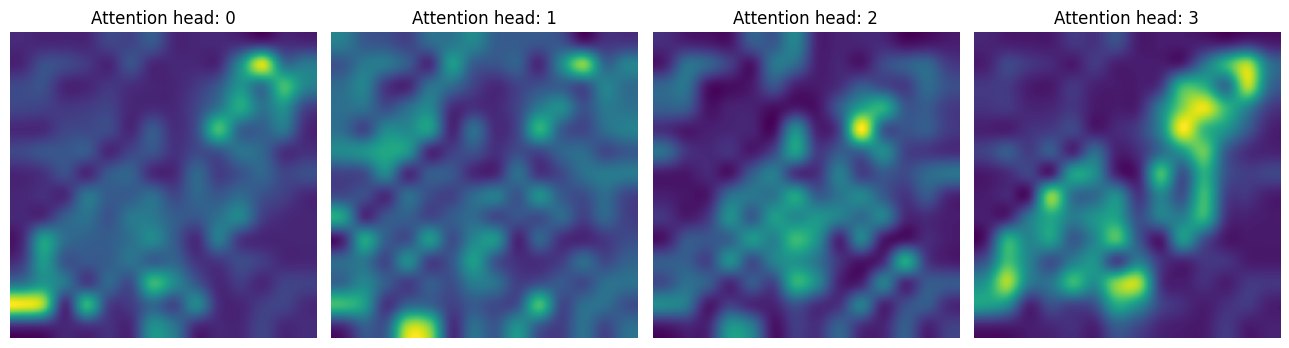
在第一個 CA 層中,我們注意到該模型僅關注感興趣的區域。
attentions_ca_block_0 = get_cls_attention_map(ca_ffn_block_0_att)
fig, axes = plt.subplots(nrows=1, ncols=4, figsize=(13, 13))
img_count = 0
for i in range(attentions_ca_block_0.shape[-1]):
if img_count < attentions_ca_block_0.shape[-1]:
axes[i].imshow(attentions_ca_block_0[:, :, img_count])
axes[i].title.set_text(f"Attention head: {img_count}")
axes[i].axis("off")
img_count += 1
fig.tight_layout()
plt.show()
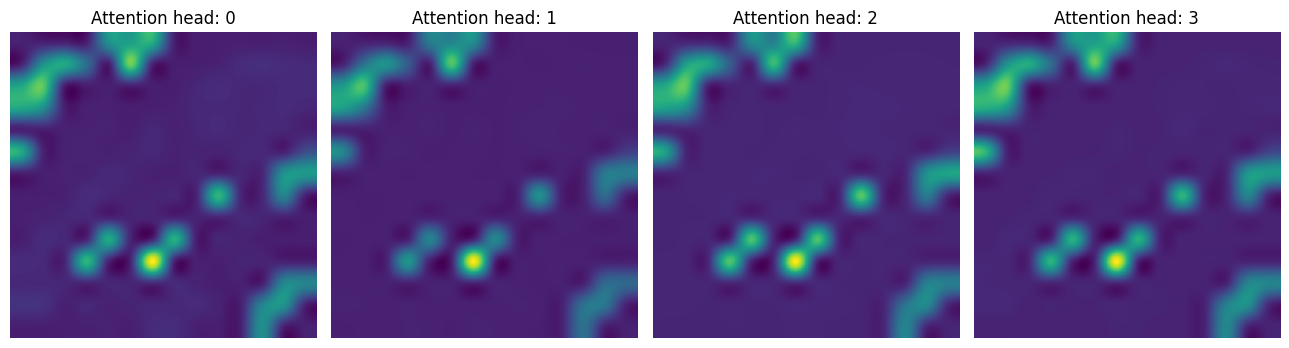
而在第二個 CA 層中,該模型嘗試更關注包含區別性訊號的上下文。
attentions_ca_block_1 = get_cls_attention_map(ca_ffn_block_1_att)
fig, axes = plt.subplots(nrows=1, ncols=4, figsize=(13, 13))
img_count = 0
for i in range(attentions_ca_block_1.shape[-1]):
if img_count < attentions_ca_block_1.shape[-1]:
axes[i].imshow(attentions_ca_block_1[:, :, img_count])
axes[i].title.set_text(f"Attention head: {img_count}")
axes[i].axis("off")
img_count += 1
fig.tight_layout()
plt.show()
最後,我們取得給定影像的顯著圖。
saliency_attention = get_cls_attention_map(ca_ffn_block_0_att, return_saliency=True)
image = np.array(image)
image_resized = ops.expand_dims(image, 0)
resize_size = int((256 / 224) * image_size)
image_resized = ops.image.resize(
image_resized, (resize_size, resize_size), interpolation="bicubic"
)
image_resized = crop_layer(image_resized)
plt.imshow(image_resized.numpy().squeeze().astype("int32"))
plt.imshow(saliency_attention.numpy().squeeze(), cmap="cividis", alpha=0.9)
plt.axis("off")
plt.show()

結論
在本筆記本中,我們實作了 CaiT 模型。它說明了如何在嘗試擴展深度時緩解 ViT 中的問題,同時保持預先訓練的資料集固定。我希望筆記本中提供的其他視覺化效果能激發社群的興趣,並讓人們開發有趣的方法來探測 ViT 等模型所學習的內容。
致謝
感謝 Google 的 ML 開發人員計畫團隊提供 Google Cloud Platform 支援。