使用全局上下文視覺轉換器進行圖像分類
作者: Md Awsafur Rahman
建立日期 2023/10/30
上次修改日期 2023/10/30
描述: 全局上下文視覺轉換器在圖像分類上的實作和微調。

設定
!pip install --upgrade keras_cv tensorflow
!pip install --upgrade keras
import keras
from keras_cv.layers import DropPath
from keras import ops
from keras import layers
import tensorflow as tf # only for dataloader
import tensorflow_datasets as tfds # for flower dataset
from skimage.data import chelsea
import matplotlib.pyplot as plt
import numpy as np
簡介
在本筆記本中,我們將利用多後端 Keras 3.0 來實作 GCViT:全局上下文視覺轉換器論文,該論文由 A Hatamizadeh 等人在 ICML 2023 上發表。然後,我們將在 Flower 數據集上微調該模型以進行圖像分類任務,並利用官方 ImageNet 預訓練權重。本筆記本的重點是其與多個後端的相容性:TensorFlow、PyTorch 和 JAX,展示了多後端 Keras 的真正潛力。
動機
注意: 在本節中,我們將了解 GCViT 的背景故事,並嘗試了解為什麼提出它。
- 近年來,轉換器在自然語言處理 (NLP) 任務中取得了主導地位,其自我注意力機制允許捕捉長距離和短距離資訊。
- 順應這一趨勢,視覺轉換器 (ViT) 提出在類似於原始轉換器編碼器的巨大架構中使用圖像區塊作為標記。
- 儘管卷積神經網路 (CNN) 在電腦視覺領域具有歷史優勢,但基於 ViT 的模型在各種電腦視覺任務中都展現出 SOTA 或具競爭力的效能。
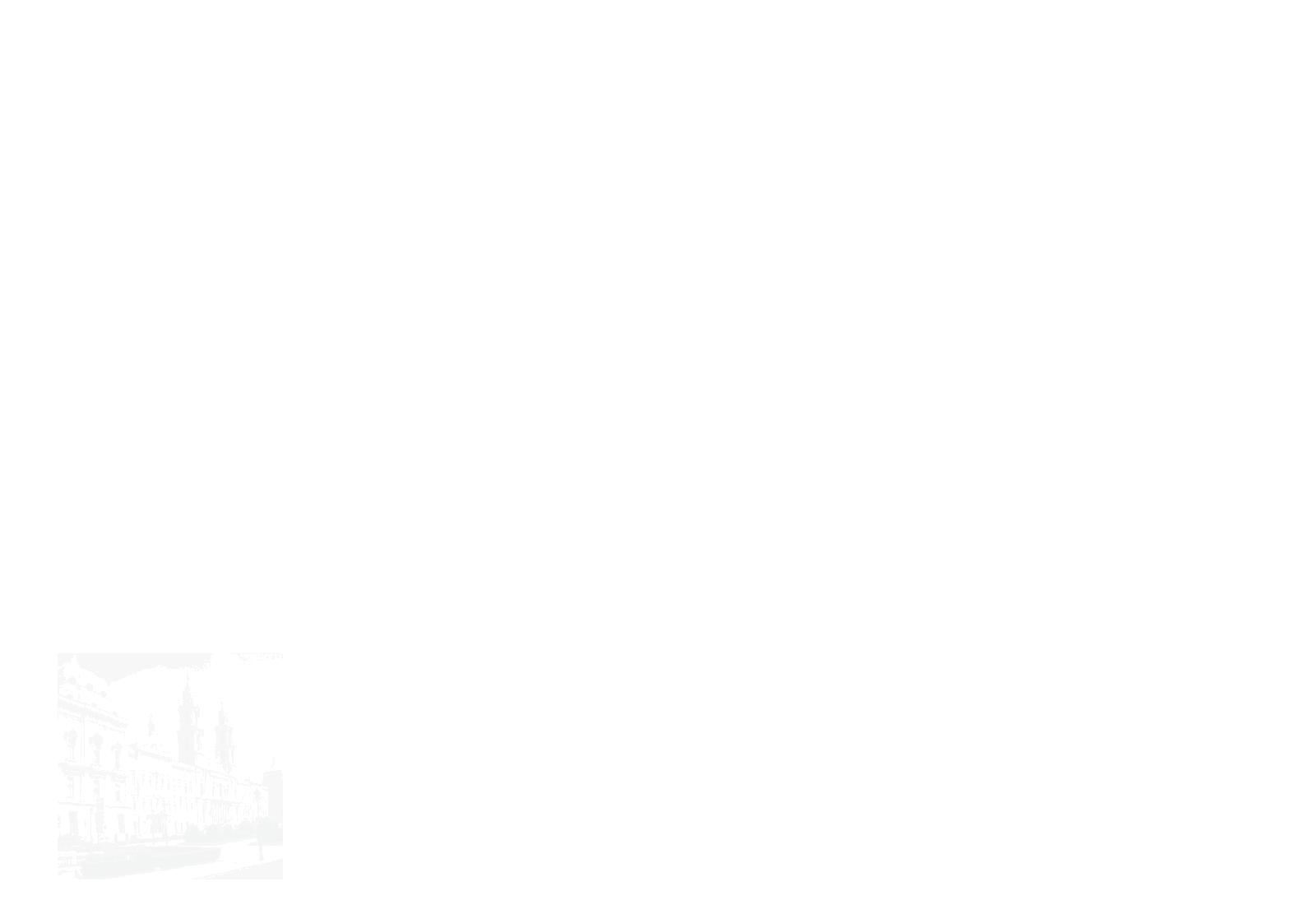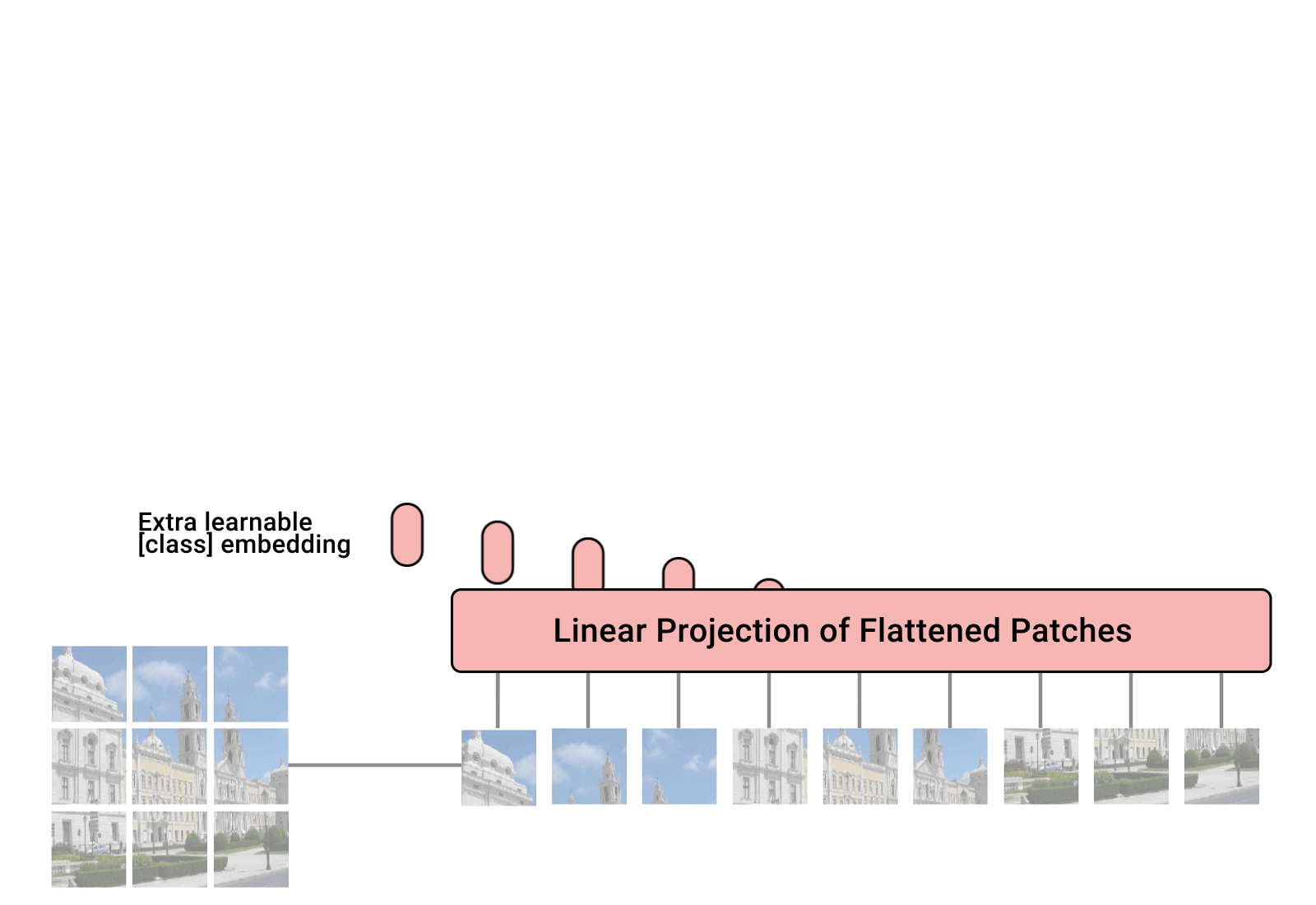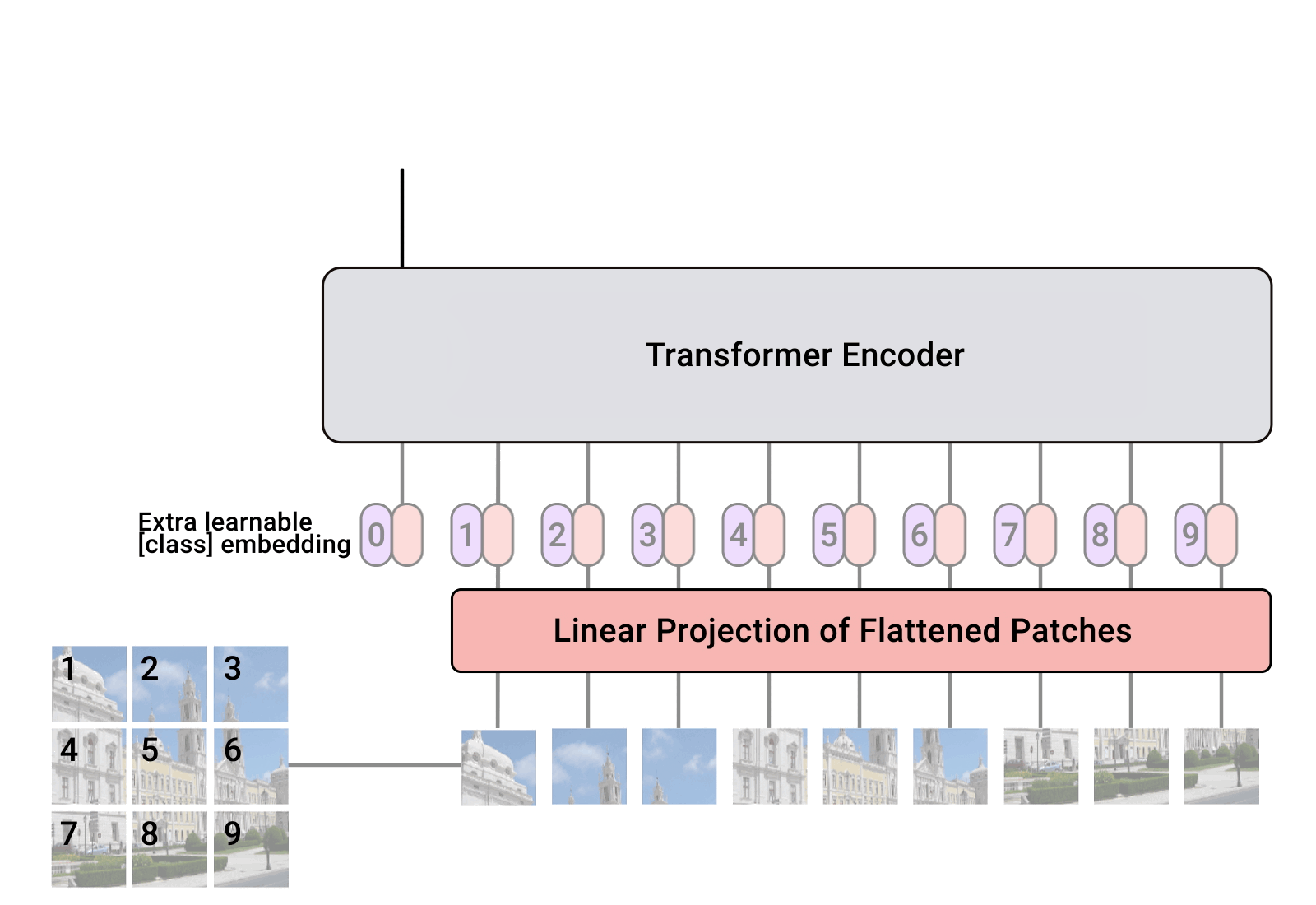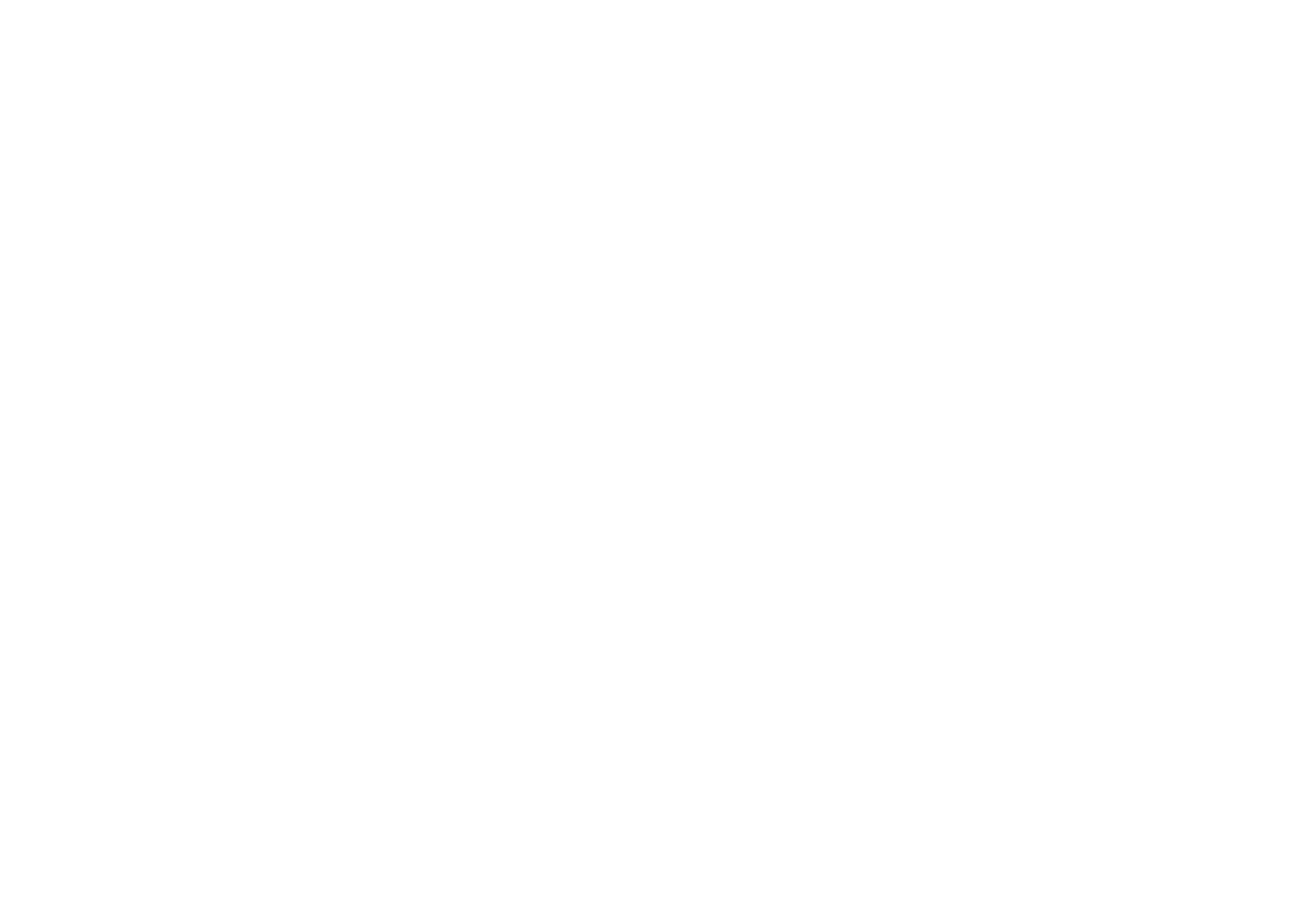
- 然而,自我注意力的二次方 [
O(n^2)] 計算複雜度和缺乏多尺度資訊使得 ViT 難以被視為電腦視覺任務(如分割和物件偵測)的通用架構,在這些任務中,它需要在像素級別進行密集預測。 - Swin 轉換器試圖透過提出多解析度/分層架構來解決 ViT 的問題,在該架構中,自我注意力在局部窗口中計算,並且使用諸如窗口移動之類的跨窗口連接來建模不同區域之間的互動。但是,局部窗口的有限感受野無法捕獲長距離資訊,並且諸如窗口移動之類的跨窗口連接方案僅涵蓋每個窗口附近的一小部分鄰域。此外,它缺乏鼓勵特定平移不變性的歸納偏差,對於通用視覺建模,尤其是在物件偵測和語義分割的密集預測任務中,仍然是首選。
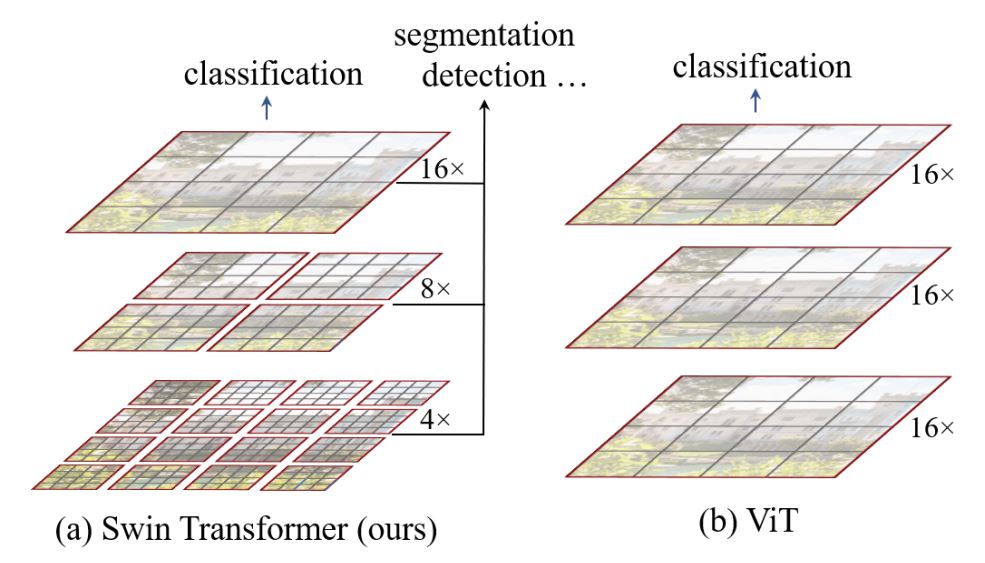
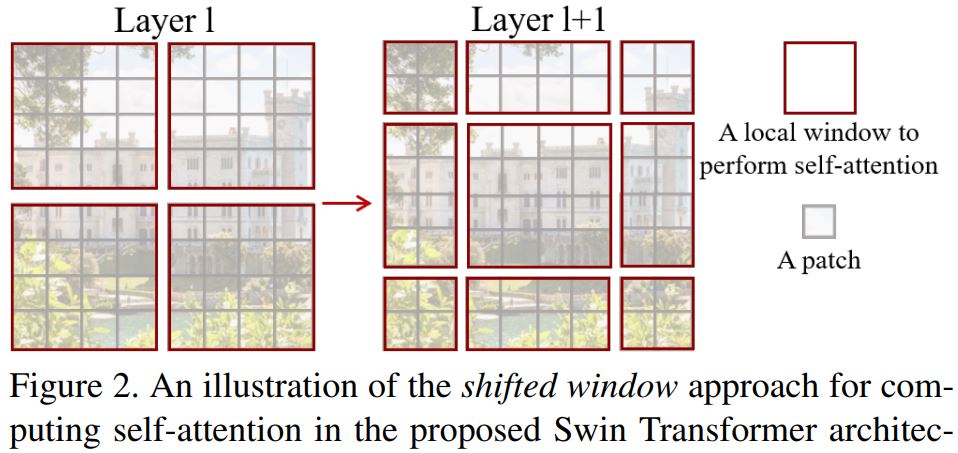
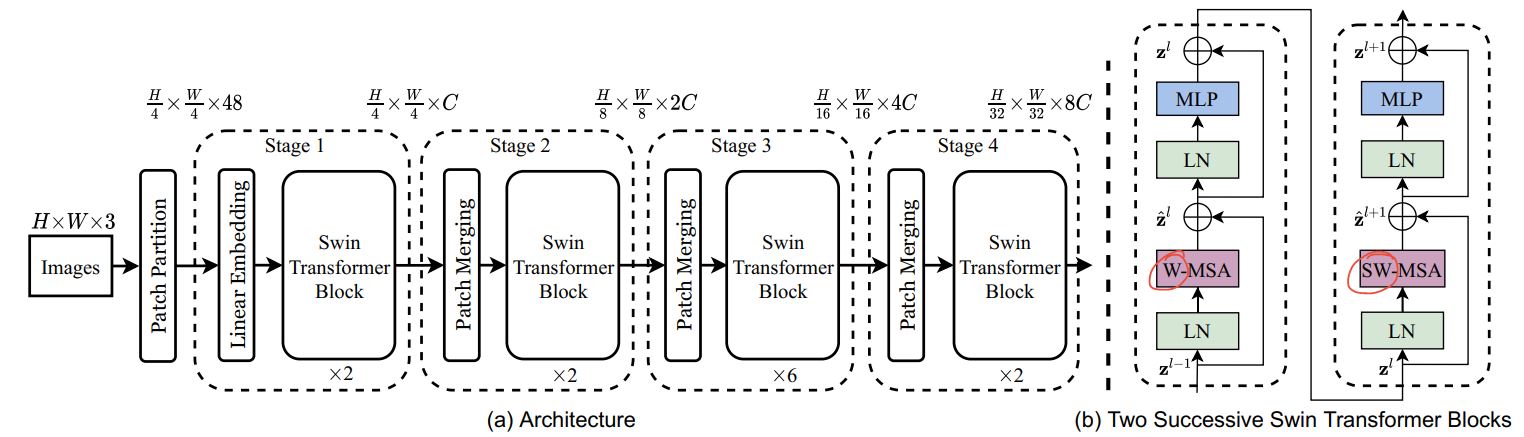
- 為了應對上述限制,提出了 全局上下文 (GC) ViT 網路。
架構
讓我們快速概述我們的關鍵組件,1. Stem/PatchEmbed: stem/patchify 層在網路的開頭處理圖像。對於此網路,它會建立區塊/標記並將它們轉換為嵌入。2. Level:它是重複的構建模組,使用不同的區塊提取特徵。3. Global Token Gen./FeatureExtraction:它使用深度卷積網路 (Depthwise-CNN)、擠壓與激勵 (SqueezeAndExcitation)、CNN 和 MaxPooling 產生全局標記/區塊。所以基本上它是一個特徵提取器。4. Block:它是重複的模組,將注意力應用於特徵並將它們投影到特定的維度。1. Local-MSA:局部多頭自我注意力。2. Global-MSA:全局多頭自我注意力。3. MLP:將向量投影到另一個維度的線性層。5. Downsample/ReduceSize:它與全局標記生成模組非常相似,不同之處在於它使用 CNN 而不是 MaxPooling 來進行降採樣,並帶有額外的層正規化模組。6. Head:它是負責分類任務的模組。1. Pooling:它將 N x 2D 特徵轉換為 N x 1D 特徵。2. Classifier:它處理 N x 1D 特徵,以決定類別。
我註解了架構圖,使其更容易理解,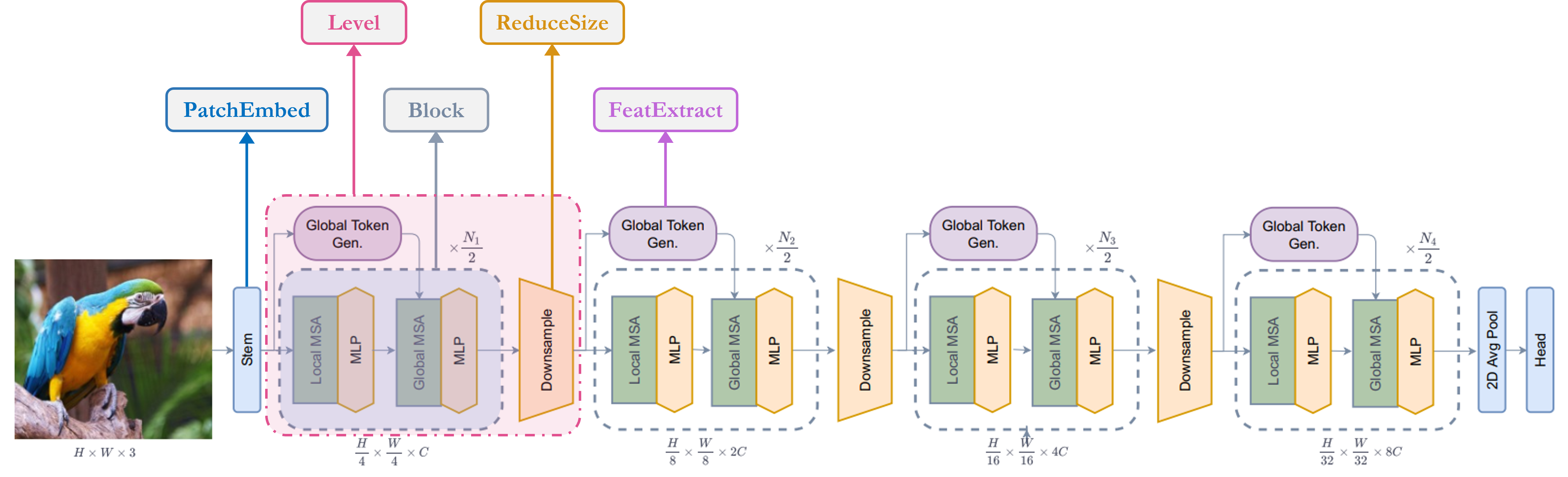
單元區塊
注意: 這些區塊用於在整篇論文中建構其他模組。大多數區塊要么是從其他工作中借來的,要么是舊工作的修改版本。
-
SqueezeAndExcitation:擠壓-激勵 (SE) 又名瓶頸模組充當一種通道注意力。它包含平均池化 (AvgPooling)、稠密/全連接 (FC)/線性、GELU 和 Sigmoid 模組。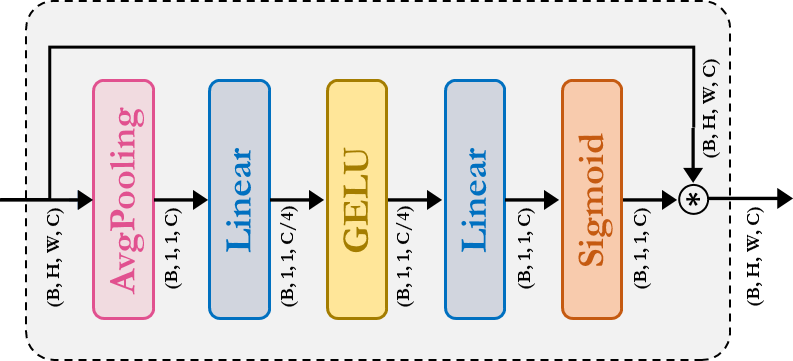
-
Fused-MBConv:這與 EfficientNetV2 中使用的類似。它使用Depthwise-Conv、GELU、SqueezeAndExcitation、Conv 來提取特徵,並具有殘差連接。請注意,此模組沒有宣告新的模組,我們只是直接應用了對應的模組。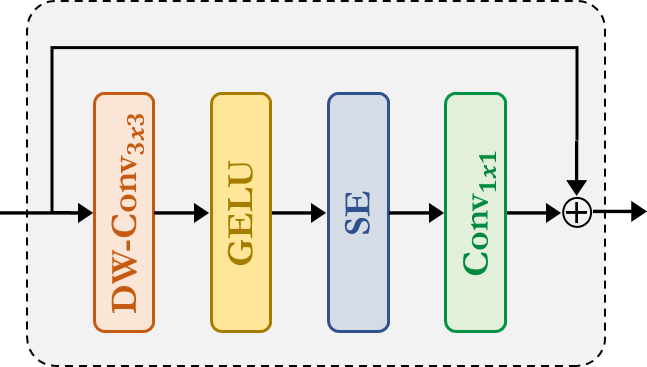
-
ReduceSize:這是一個基於 CNN 的降採樣模組,它使用前面提到的Fused-MBConv模組來提取特徵,使用步幅卷積 (Strided Conv) 同時減少空間維度並增加特徵的通道維度,最後使用 LayerNormalization 模組來正規化特徵。在論文/圖表中,此模組被稱為降採樣模組。我認為值得一提的是,SwinTransformer 使用PatchMerging模組而不是ReduceSize來減少空間維度並增加通道維度,而PatchMerging模組使用全連接/密集/線性模組。根據 GCViT 論文,使用ReduceSize的目的之一是透過 CNN 模組添加歸納偏置。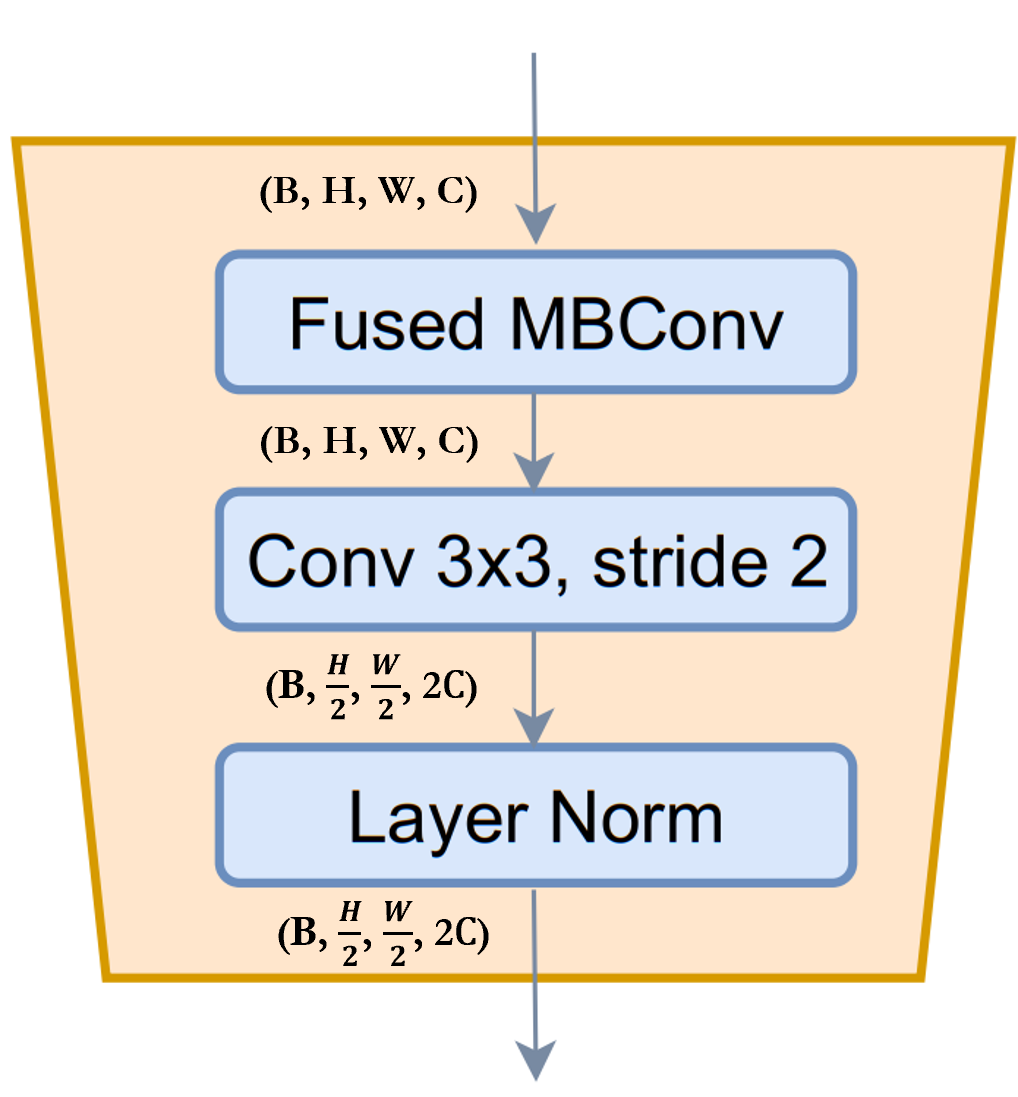
-
MLP:這是一個我們自己的 多層感知器 (Multi Layer Perceptron) 模組。這是一個前饋/全連接/線性模組,它只是將輸入投影到任意維度。
class SqueezeAndExcitation(layers.Layer):
"""Squeeze and excitation block.
Args:
output_dim: output features dimension, if `None` use same dim as input.
expansion: expansion ratio.
"""
def __init__(self, output_dim=None, expansion=0.25, **kwargs):
super().__init__(**kwargs)
self.expansion = expansion
self.output_dim = output_dim
def build(self, input_shape):
inp = input_shape[-1]
self.output_dim = self.output_dim or inp
self.avg_pool = layers.GlobalAvgPool2D(keepdims=True, name="avg_pool")
self.fc = [
layers.Dense(int(inp * self.expansion), use_bias=False, name="fc_0"),
layers.Activation("gelu", name="fc_1"),
layers.Dense(self.output_dim, use_bias=False, name="fc_2"),
layers.Activation("sigmoid", name="fc_3"),
]
super().build(input_shape)
def call(self, inputs, **kwargs):
x = self.avg_pool(inputs)
for layer in self.fc:
x = layer(x)
return x * inputs
class ReduceSize(layers.Layer):
"""Down-sampling block.
Args:
keepdims: if False spatial dim is reduced and channel dim is increased
"""
def __init__(self, keepdims=False, **kwargs):
super().__init__(**kwargs)
self.keepdims = keepdims
def build(self, input_shape):
embed_dim = input_shape[-1]
dim_out = embed_dim if self.keepdims else 2 * embed_dim
self.pad1 = layers.ZeroPadding2D(1, name="pad1")
self.pad2 = layers.ZeroPadding2D(1, name="pad2")
self.conv = [
layers.DepthwiseConv2D(
kernel_size=3, strides=1, padding="valid", use_bias=False, name="conv_0"
),
layers.Activation("gelu", name="conv_1"),
SqueezeAndExcitation(name="conv_2"),
layers.Conv2D(
embed_dim,
kernel_size=1,
strides=1,
padding="valid",
use_bias=False,
name="conv_3",
),
]
self.reduction = layers.Conv2D(
dim_out,
kernel_size=3,
strides=2,
padding="valid",
use_bias=False,
name="reduction",
)
self.norm1 = layers.LayerNormalization(
-1, 1e-05, name="norm1"
) # eps like PyTorch
self.norm2 = layers.LayerNormalization(-1, 1e-05, name="norm2")
def call(self, inputs, **kwargs):
x = self.norm1(inputs)
xr = self.pad1(x)
for layer in self.conv:
xr = layer(xr)
x = x + xr
x = self.pad2(x)
x = self.reduction(x)
x = self.norm2(x)
return x
class MLP(layers.Layer):
"""Multi-Layer Perceptron (MLP) block.
Args:
hidden_features: hidden features dimension.
out_features: output features dimension.
activation: activation function.
dropout: dropout rate.
"""
def __init__(
self,
hidden_features=None,
out_features=None,
activation="gelu",
dropout=0.0,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_features = hidden_features
self.out_features = out_features
self.activation = activation
self.dropout = dropout
def build(self, input_shape):
self.in_features = input_shape[-1]
self.hidden_features = self.hidden_features or self.in_features
self.out_features = self.out_features or self.in_features
self.fc1 = layers.Dense(self.hidden_features, name="fc1")
self.act = layers.Activation(self.activation, name="act")
self.fc2 = layers.Dense(self.out_features, name="fc2")
self.drop1 = layers.Dropout(self.dropout, name="drop1")
self.drop2 = layers.Dropout(self.dropout, name="drop2")
def call(self, inputs, **kwargs):
x = self.fc1(inputs)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
Stem (詞幹)
註解:在程式碼中,此模組稱為 PatchEmbed,但在論文中,它稱為 Stem。
在模型中,我們首先使用了 patch_embed 模組。讓我們嘗試理解這個模組。從 call 方法中可以看到: 1. 此模組首先填充 (pads) 輸入。 2. 然後使用卷積 (convolutions) 來提取帶有嵌入的塊 (patches)。 3. 最後,使用 ReduceSize 模組先使用卷積提取特徵,但既不減少空間維度也不增加空間維度。 4. 一個需要注意的重點是,與 ViT 或 SwinTransformer 不同,GCViT 創建的是重疊的塊 (overlapping patches)。我們可以從程式碼中看到: Conv2D(self.embed_dim, kernel_size=3, strides=2, name='proj')。如果我們想要非重疊的塊,那麼我們應該使用相同的 kernel_size 和 stride。 5. 此模組將輸入的空間維度減少 4x。
總結:圖像 → 填充 → 卷積 → (特徵提取 + 降採樣)
class PatchEmbed(layers.Layer):
"""Patch embedding block.
Args:
embed_dim: feature size dimension.
"""
def __init__(self, embed_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
def build(self, input_shape):
self.pad = layers.ZeroPadding2D(1, name="pad")
self.proj = layers.Conv2D(self.embed_dim, 3, 2, name="proj")
self.conv_down = ReduceSize(keepdims=True, name="conv_down")
def call(self, inputs, **kwargs):
x = self.pad(inputs)
x = self.proj(x)
x = self.conv_down(x)
return x
Global Token Gen. (全局標記生成)
註解: 這是用來施加歸納偏置的兩個 CNN 模組之一。
從上面的單元格中可以看到,在 level 中,我們首先使用了 to_q_global/Global Token Gen./FeatureExtraction。讓我們嘗試理解它的工作原理。
- 此模組是一系列的
FeatureExtract模組,根據論文,我們需要重複此模組K次,其中K = log2(H/h),H = 特徵圖高度,W = 特徵圖寬度。 FeatureExtraction:這個層與ReduceSize模組非常相似,只是它使用 MaxPooling 模組來減少維度,它不增加特徵維度(通道),也不使用 LayerNormalizaton。此模組在Generate Token Gen.模組中重複使用,以生成用於全局上下文注意力 (global-context-attention) 的全局標記 (global tokens)。- 從圖中需要注意的一個重點是,全局標記在整個圖像中共享,這表示我們在一個圖像中,針對所有局部標記 (local tokens) 只使用一個全局視窗 (global window)。這使得計算非常有效率。
- 對於形狀為
(B, H, W, C)的輸入特徵圖,我們將獲得形狀為(B, h, w, C)的輸出。如果我們將這些全局標記複製到一個圖像中的總共M個局部視窗中,其中M = (H x W)/(h x w) = num_window,則輸出形狀為:(B * M, h, w, C)。"
總結:此模組用於調整圖像大小以適合視窗。
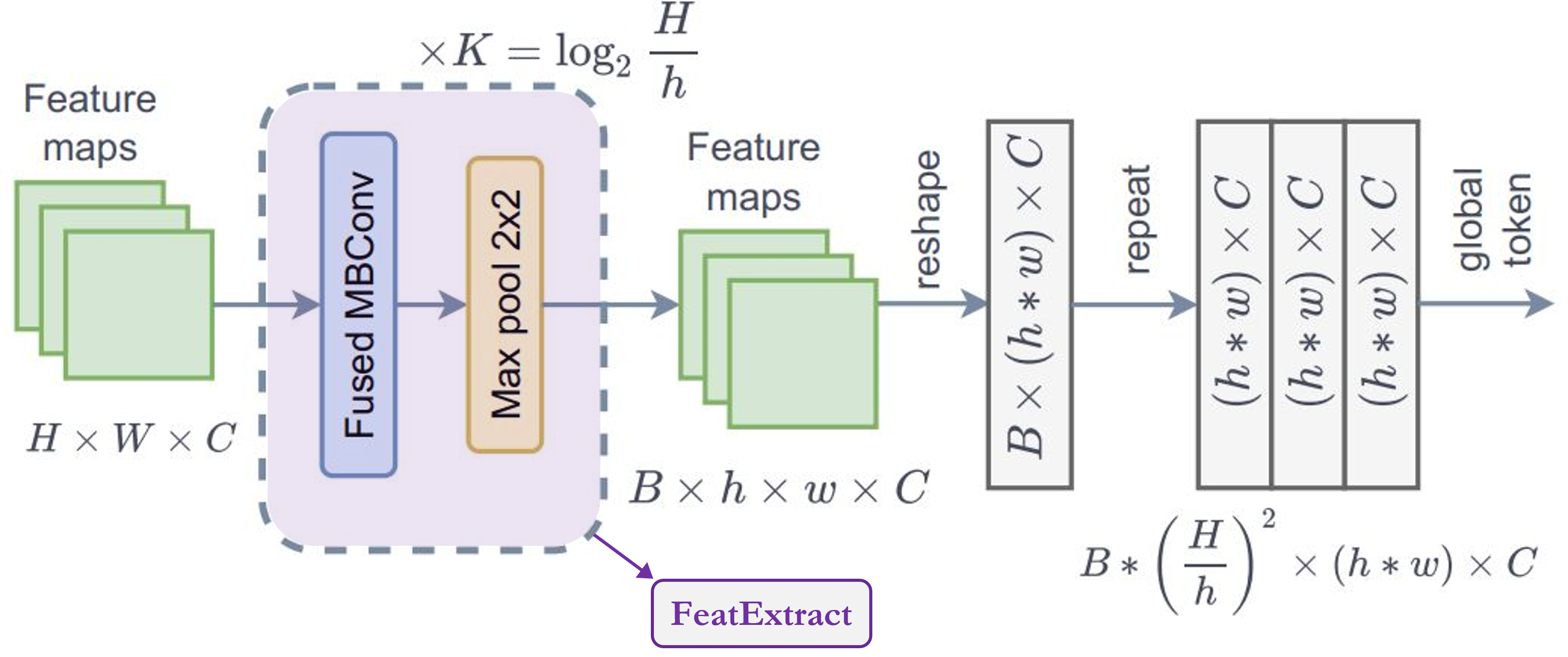
class FeatureExtraction(layers.Layer):
"""Feature extraction block.
Args:
keepdims: bool argument for maintaining the resolution.
"""
def __init__(self, keepdims=False, **kwargs):
super().__init__(**kwargs)
self.keepdims = keepdims
def build(self, input_shape):
embed_dim = input_shape[-1]
self.pad1 = layers.ZeroPadding2D(1, name="pad1")
self.pad2 = layers.ZeroPadding2D(1, name="pad2")
self.conv = [
layers.DepthwiseConv2D(3, 1, use_bias=False, name="conv_0"),
layers.Activation("gelu", name="conv_1"),
SqueezeAndExcitation(name="conv_2"),
layers.Conv2D(embed_dim, 1, 1, use_bias=False, name="conv_3"),
]
if not self.keepdims:
self.pool = layers.MaxPool2D(3, 2, name="pool")
super().build(input_shape)
def call(self, inputs, **kwargs):
x = inputs
xr = self.pad1(x)
for layer in self.conv:
xr = layer(xr)
x = x + xr
if not self.keepdims:
x = self.pool(self.pad2(x))
return x
class GlobalQueryGenerator(layers.Layer):
"""Global query generator.
Args:
keepdims: to keep the dimension of FeatureExtraction layer.
For instance, repeating log(56/7) = 3 blocks, with input
window dimension 56 and output window dimension 7 at down-sampling
ratio 2. Please check Fig.5 of GC ViT paper for details.
"""
def __init__(self, keepdims=False, **kwargs):
super().__init__(**kwargs)
self.keepdims = keepdims
def build(self, input_shape):
self.to_q_global = [
FeatureExtraction(keepdims, name=f"to_q_global_{i}")
for i, keepdims in enumerate(self.keepdims)
]
super().build(input_shape)
def call(self, inputs, **kwargs):
x = inputs
for layer in self.to_q_global:
x = layer(x)
return x
注意力
註解: 這是論文的核心貢獻。
從 call 方法中可以看到: 1. WindowAttention 模組根據 global_query 參數應用局部和全局視窗注意力。
- 首先,它將輸入特徵轉換為局部注意力的
query, key, value,以及全局注意力的key, value。對於全局注意力,它從Global Token Gen.取得全局查詢。從程式碼中需要注意的一件事是,我們將特徵或 embed_dim 分配給Transformer 的所有頭 (heads),以減少計算量。qkv = tf.reshape(qkv, [B_, N, self.qkv_size, self.num_heads, C // self.num_heads]) - 在將查詢、鍵和值發送以進行注意力計算之前,全局標記會經過一個重要的過程。相同的全局標記或一個全局視窗會被複製到所有局部視窗,以提高效率。
q_global = tf.repeat(q_global, repeats=B_//B, axis=0),這裡B_//B表示一個圖像中的num_windows。 - 然後根據
global_query參數簡單地應用local-window-self-attention或global-window-attention。從程式碼中需要注意的一件事是,我們將相對位置嵌入 (relative-positional-embedding) 與注意力遮罩 (attention mask) 相加,而不是與塊嵌入 (patch embedding) 相加。attn = attn + relative_position_bias[tf.newaxis,]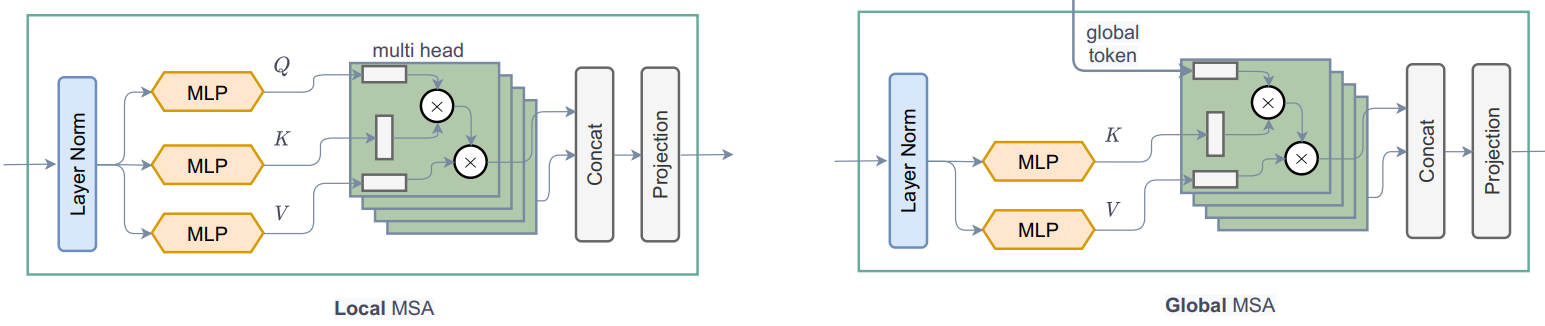
- 現在,讓我們思考一下,嘗試理解這裡發生的事情。讓我們把注意力放在下圖上。從左邊可以看到,在局部注意力中,查詢是局部的,並且它被限制在局部視窗(紅色正方形邊框)中,因此我們無法存取遠程資訊。但是在右邊,由於全局查詢,我們現在不受限於局部視窗(藍色正方形邊框),並且我們可以存取遠程資訊。
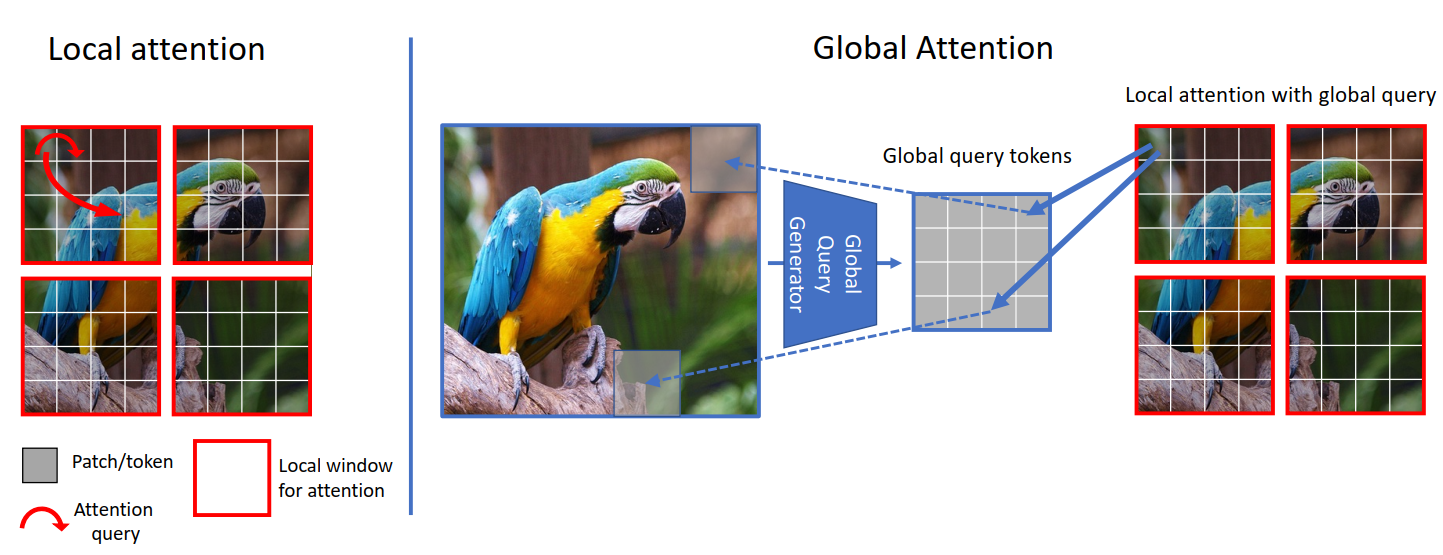
- 在 ViT 中,我們將圖像標記與圖像標記進行比較(注意力計算),在 SwinTransformer 中,我們將視窗標記與視窗標記進行比較,但在 GCViT 中,我們將圖像標記與視窗標記進行比較。但現在你可能會問,即使圖像標記的維度大於視窗標記,我們如何將圖像標記與視窗標記進行比較(注意力計算)?(從上圖可見,圖像標記的形狀為
(1, 8, 8, 3),而視窗標記的形狀為(1, 4, 4, 3))。是的,你是對的,我們不能直接比較它們,因此我們使用Global Token Gen./FeatureExtractionCNN 模組將圖像標記調整大小以適合視窗標記。下表應可給你清楚的比較:
| 模型 | 查詢標記 | 鍵值標記 | 注意力類型 | 注意力覆蓋範圍 |
|---|---|---|---|---|
| ViT | 圖像 | 圖像 | 自我注意力 | 全局 |
| SwinTransformer | 視窗 | 視窗 | 自我注意力 | 局部 |
| GCViT | 調整大小後的圖像 | 視窗 | 圖像視窗注意力 | 全局 |
class WindowAttention(layers.Layer):
"""Local window attention.
This implementation was proposed by
[Liu et al., 2021](https://arxiv.org/abs/2103.14030) in SwinTransformer.
Args:
window_size: window size.
num_heads: number of attention head.
global_query: if the input contains global_query
qkv_bias: bool argument for query, key, value learnable bias.
qk_scale: bool argument to scaling query, key.
attention_dropout: attention dropout rate.
projection_dropout: output dropout rate.
"""
def __init__(
self,
window_size,
num_heads,
global_query,
qkv_bias=True,
qk_scale=None,
attention_dropout=0.0,
projection_dropout=0.0,
**kwargs,
):
super().__init__(**kwargs)
window_size = (window_size, window_size)
self.window_size = window_size
self.num_heads = num_heads
self.global_query = global_query
self.qkv_bias = qkv_bias
self.qk_scale = qk_scale
self.attention_dropout = attention_dropout
self.projection_dropout = projection_dropout
def build(self, input_shape):
embed_dim = input_shape[0][-1]
head_dim = embed_dim // self.num_heads
self.scale = self.qk_scale or head_dim**-0.5
self.qkv_size = 3 - int(self.global_query)
self.qkv = layers.Dense(
embed_dim * self.qkv_size, use_bias=self.qkv_bias, name="qkv"
)
self.relative_position_bias_table = self.add_weight(
name="relative_position_bias_table",
shape=[
(2 * self.window_size[0] - 1) * (2 * self.window_size[1] - 1),
self.num_heads,
],
initializer=keras.initializers.TruncatedNormal(stddev=0.02),
trainable=True,
dtype=self.dtype,
)
self.attn_drop = layers.Dropout(self.attention_dropout, name="attn_drop")
self.proj = layers.Dense(embed_dim, name="proj")
self.proj_drop = layers.Dropout(self.projection_dropout, name="proj_drop")
self.softmax = layers.Activation("softmax", name="softmax")
super().build(input_shape)
def get_relative_position_index(self):
coords_h = ops.arange(self.window_size[0])
coords_w = ops.arange(self.window_size[1])
coords = ops.stack(ops.meshgrid(coords_h, coords_w, indexing="ij"), axis=0)
coords_flatten = ops.reshape(coords, [2, -1])
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = ops.transpose(relative_coords, axes=[1, 2, 0])
relative_coords_xx = relative_coords[:, :, 0] + self.window_size[0] - 1
relative_coords_yy = relative_coords[:, :, 1] + self.window_size[1] - 1
relative_coords_xx = relative_coords_xx * (2 * self.window_size[1] - 1)
relative_position_index = relative_coords_xx + relative_coords_yy
return relative_position_index
def call(self, inputs, **kwargs):
if self.global_query:
inputs, q_global = inputs
B = ops.shape(q_global)[0] # B, N, C
else:
inputs = inputs[0]
B_, N, C = ops.shape(inputs) # B*num_window, num_tokens, channels
qkv = self.qkv(inputs)
qkv = ops.reshape(
qkv, [B_, N, self.qkv_size, self.num_heads, C // self.num_heads]
)
qkv = ops.transpose(qkv, [2, 0, 3, 1, 4])
if self.global_query:
k, v = ops.split(
qkv, indices_or_sections=2, axis=0
) # for unknown shame num=None will throw error
q_global = ops.repeat(
q_global, repeats=B_ // B, axis=0
) # num_windows = B_//B => q_global same for all windows in a img
q = ops.reshape(q_global, [B_, N, self.num_heads, C // self.num_heads])
q = ops.transpose(q, axes=[0, 2, 1, 3])
else:
q, k, v = ops.split(qkv, indices_or_sections=3, axis=0)
q = ops.squeeze(q, axis=0)
k = ops.squeeze(k, axis=0)
v = ops.squeeze(v, axis=0)
q = q * self.scale
attn = q @ ops.transpose(k, axes=[0, 1, 3, 2])
relative_position_bias = ops.take(
self.relative_position_bias_table,
ops.reshape(self.get_relative_position_index(), [-1]),
)
relative_position_bias = ops.reshape(
relative_position_bias,
[
self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1],
-1,
],
)
relative_position_bias = ops.transpose(relative_position_bias, axes=[2, 0, 1])
attn = attn + relative_position_bias[None,]
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = ops.transpose((attn @ v), axes=[0, 2, 1, 3])
x = ops.reshape(x, [B_, N, C])
x = self.proj_drop(self.proj(x))
return x
區塊
註解: 此模組沒有任何卷積模組。
在 level 中,我們使用的第二個模組是 block。讓我們嘗試理解它的工作原理。從 call 方法中可以看到: 1. Block 模組僅接受用於局部注意力的特徵圖,或接受用於全局注意力的額外全局查詢。 2. 在將特徵圖發送以進行注意力計算之前,此模組會將批次特徵圖 (batch feature maps) 轉換為批次視窗 (batch windows),因為我們將應用視窗注意力。 3. 然後,我們將批次批次視窗發送以進行注意力計算。 4. 在應用注意力計算之後,我們將批次視窗還原為批次特徵圖。 5. 在將注意力應用於輸出的特徵之前,此模組在殘差連接中應用隨機深度 (Stochastic Depth) 正規化。另外,在應用隨機深度之前,它會使用可訓練的參數重新縮放輸入。請注意,此隨機深度區塊未在論文的圖表中顯示。
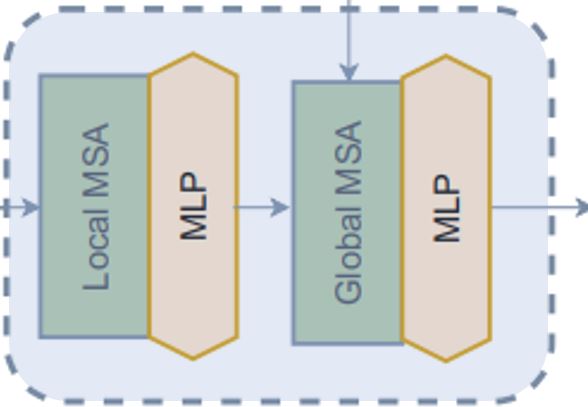
視窗
在 block 模組中,我們在應用注意力之前和之後都創建了視窗。讓我們嘗試理解我們如何創建視窗: * 下列模組將特徵圖 (B, H, W, C) 轉換為堆疊的視窗 (B x H/h x W/w, h, w, C) → (num_windows_batch, window_size, window_size, channel) * 此模組使用 reshape 和 transpose 從圖像中創建這些視窗,而不是迭代它們。
class Block(layers.Layer):
"""GCViT block.
Args:
window_size: window size.
num_heads: number of attention head.
global_query: apply global window attention
mlp_ratio: MLP ratio.
qkv_bias: bool argument for query, key, value learnable bias.
qk_scale: bool argument to scaling query, key.
drop: dropout rate.
attention_dropout: attention dropout rate.
path_drop: drop path rate.
activation: activation function.
layer_scale: layer scaling coefficient.
"""
def __init__(
self,
window_size,
num_heads,
global_query,
mlp_ratio=4.0,
qkv_bias=True,
qk_scale=None,
dropout=0.0,
attention_dropout=0.0,
path_drop=0.0,
activation="gelu",
layer_scale=None,
**kwargs,
):
super().__init__(**kwargs)
self.window_size = window_size
self.num_heads = num_heads
self.global_query = global_query
self.mlp_ratio = mlp_ratio
self.qkv_bias = qkv_bias
self.qk_scale = qk_scale
self.dropout = dropout
self.attention_dropout = attention_dropout
self.path_drop = path_drop
self.activation = activation
self.layer_scale = layer_scale
def build(self, input_shape):
B, H, W, C = input_shape[0]
self.norm1 = layers.LayerNormalization(-1, 1e-05, name="norm1")
self.attn = WindowAttention(
window_size=self.window_size,
num_heads=self.num_heads,
global_query=self.global_query,
qkv_bias=self.qkv_bias,
qk_scale=self.qk_scale,
attention_dropout=self.attention_dropout,
projection_dropout=self.dropout,
name="attn",
)
self.drop_path1 = DropPath(self.path_drop)
self.drop_path2 = DropPath(self.path_drop)
self.norm2 = layers.LayerNormalization(-1, 1e-05, name="norm2")
self.mlp = MLP(
hidden_features=int(C * self.mlp_ratio),
dropout=self.dropout,
activation=self.activation,
name="mlp",
)
if self.layer_scale is not None:
self.gamma1 = self.add_weight(
name="gamma1",
shape=[C],
initializer=keras.initializers.Constant(self.layer_scale),
trainable=True,
dtype=self.dtype,
)
self.gamma2 = self.add_weight(
name="gamma2",
shape=[C],
initializer=keras.initializers.Constant(self.layer_scale),
trainable=True,
dtype=self.dtype,
)
else:
self.gamma1 = 1.0
self.gamma2 = 1.0
self.num_windows = int(H // self.window_size) * int(W // self.window_size)
super().build(input_shape)
def call(self, inputs, **kwargs):
if self.global_query:
inputs, q_global = inputs
else:
inputs = inputs[0]
B, H, W, C = ops.shape(inputs)
x = self.norm1(inputs)
# create windows and concat them in batch axis
x = self.window_partition(x, self.window_size) # (B_, win_h, win_w, C)
# flatten patch
x = ops.reshape(x, [-1, self.window_size * self.window_size, C])
# attention
if self.global_query:
x = self.attn([x, q_global])
else:
x = self.attn([x])
# reverse window partition
x = self.window_reverse(x, self.window_size, H, W, C)
# FFN
x = inputs + self.drop_path1(x * self.gamma1)
x = x + self.drop_path2(self.gamma2 * self.mlp(self.norm2(x)))
return x
def window_partition(self, x, window_size):
"""
Args:
x: (B, H, W, C)
window_size: window size
Returns:
local window features (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = ops.shape(x)
x = ops.reshape(
x,
[
-1,
H // window_size,
window_size,
W // window_size,
window_size,
C,
],
)
x = ops.transpose(x, axes=[0, 1, 3, 2, 4, 5])
windows = ops.reshape(x, [-1, window_size, window_size, C])
return windows
def window_reverse(self, windows, window_size, H, W, C):
"""
Args:
windows: local window features (num_windows*B, window_size, window_size, C)
window_size: Window size
H: Height of image
W: Width of image
C: Channel of image
Returns:
x: (B, H, W, C)
"""
x = ops.reshape(
windows,
[
-1,
H // window_size,
W // window_size,
window_size,
window_size,
C,
],
)
x = ops.transpose(x, axes=[0, 1, 3, 2, 4, 5])
x = ops.reshape(x, [-1, H, W, C])
return x
層級
註解: 此模組同時具有 Transformer 和 CNN 模組。
在模型中,我們使用的第二個模組是 level。讓我們嘗試理解這個模組。從 call 方法中可以看到: 1. 首先,它使用一系列 FeatureExtraction 模組創建global_token。我們稍後會看到,FeatureExtraction 不過是一個簡單的基於 CNN 的模組。 2. 然後,它使用一系列 Block 模組,根據深度層級應用局部或全局視窗注意力。 3. 最後,它使用 ReduceSize 來減少上下文特徵 (contextualized features) 的維度。
總結:特徵圖 → 全局標記 → 局部/全局視窗注意力 → 降採樣
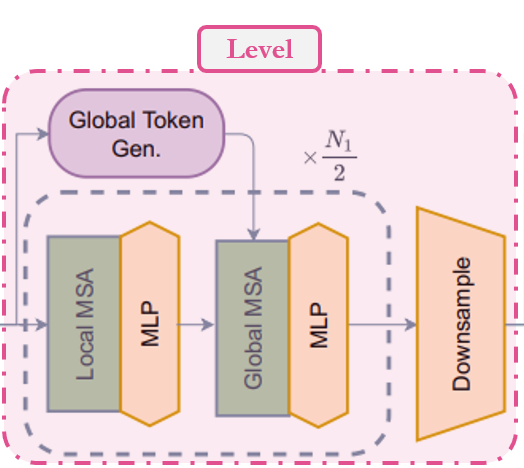
class Level(layers.Layer):
"""GCViT level.
Args:
depth: number of layers in each stage.
num_heads: number of heads in each stage.
window_size: window size in each stage.
keepdims: dims to keep in FeatureExtraction.
downsample: bool argument for down-sampling.
mlp_ratio: MLP ratio.
qkv_bias: bool argument for query, key, value learnable bias.
qk_scale: bool argument to scaling query, key.
drop: dropout rate.
attention_dropout: attention dropout rate.
path_drop: drop path rate.
layer_scale: layer scaling coefficient.
"""
def __init__(
self,
depth,
num_heads,
window_size,
keepdims,
downsample=True,
mlp_ratio=4.0,
qkv_bias=True,
qk_scale=None,
dropout=0.0,
attention_dropout=0.0,
path_drop=0.0,
layer_scale=None,
**kwargs,
):
super().__init__(**kwargs)
self.depth = depth
self.num_heads = num_heads
self.window_size = window_size
self.keepdims = keepdims
self.downsample = downsample
self.mlp_ratio = mlp_ratio
self.qkv_bias = qkv_bias
self.qk_scale = qk_scale
self.dropout = dropout
self.attention_dropout = attention_dropout
self.path_drop = path_drop
self.layer_scale = layer_scale
def build(self, input_shape):
path_drop = (
[self.path_drop] * self.depth
if not isinstance(self.path_drop, list)
else self.path_drop
)
self.blocks = [
Block(
window_size=self.window_size,
num_heads=self.num_heads,
global_query=bool(i % 2),
mlp_ratio=self.mlp_ratio,
qkv_bias=self.qkv_bias,
qk_scale=self.qk_scale,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
path_drop=path_drop[i],
layer_scale=self.layer_scale,
name=f"blocks_{i}",
)
for i in range(self.depth)
]
self.down = ReduceSize(keepdims=False, name="downsample")
self.q_global_gen = GlobalQueryGenerator(self.keepdims, name="q_global_gen")
super().build(input_shape)
def call(self, inputs, **kwargs):
x = inputs
q_global = self.q_global_gen(x) # shape: (B, win_size, win_size, C)
for i, blk in enumerate(self.blocks):
if i % 2:
x = blk([x, q_global]) # shape: (B, H, W, C)
else:
x = blk([x]) # shape: (B, H, W, C)
if self.downsample:
x = self.down(x) # shape: (B, H//2, W//2, 2*C)
return x
模型
讓我們直接跳到模型。從 call 方法中可以看到: 1. 它從圖像中創建塊嵌入。此層不會展平這些嵌入,這表示此模組的輸出將為 (batch, height/window_size, width/window_size, embed_dim),而不是 (batch, height x width/window_size^2, embed_dim)。 2. 然後,它應用 Dropout 模組,該模組隨機將輸入單元設為 0。 3. 它將這些嵌入傳遞給一系列 Level 模組,我們將這些模組稱為 level,其中: 1. 生成全局標記 1. 應用局部和全局注意力 1. 最後應用降採樣。 4. 因此,在 n 個層級之後的輸出形狀為: (batch, width/window_size x 2^{n-1}, width/window_size x 2^{n-1}, embed_dim x 2^{n-1})。在最後一層,論文不使用降採樣並增加通道。 5. 上層的輸出使用 LayerNormalization 模組進行正規化。 6. 在頭部,2D 特徵透過 Pooling 模組轉換為 1D 特徵。此模組之後的輸出形狀為 (batch, embed_dim x 2^{n-1}) 7. 最後,將池化的特徵發送到 Dense/Linear 模組進行分類。
總結:圖像 → (塊 + 嵌入) → dropout → (注意力 + 特徵提取) → 正規化 → 池化 → 分類
class GCViT(keras.Model):
"""GCViT model.
Args:
window_size: window size in each stage.
embed_dim: feature size dimension.
depths: number of layers in each stage.
num_heads: number of heads in each stage.
drop_rate: dropout rate.
mlp_ratio: MLP ratio.
qkv_bias: bool argument for query, key, value learnable bias.
qk_scale: bool argument to scaling query, key.
attention_dropout: attention dropout rate.
path_drop: drop path rate.
layer_scale: layer scaling coefficient.
num_classes: number of classes.
head_activation: activation function for head.
"""
def __init__(
self,
window_size,
embed_dim,
depths,
num_heads,
drop_rate=0.0,
mlp_ratio=3.0,
qkv_bias=True,
qk_scale=None,
attention_dropout=0.0,
path_drop=0.1,
layer_scale=None,
num_classes=1000,
head_activation="softmax",
**kwargs,
):
super().__init__(**kwargs)
self.window_size = window_size
self.embed_dim = embed_dim
self.depths = depths
self.num_heads = num_heads
self.drop_rate = drop_rate
self.mlp_ratio = mlp_ratio
self.qkv_bias = qkv_bias
self.qk_scale = qk_scale
self.attention_dropout = attention_dropout
self.path_drop = path_drop
self.layer_scale = layer_scale
self.num_classes = num_classes
self.head_activation = head_activation
self.patch_embed = PatchEmbed(embed_dim=embed_dim, name="patch_embed")
self.pos_drop = layers.Dropout(drop_rate, name="pos_drop")
path_drops = np.linspace(0.0, path_drop, sum(depths))
keepdims = [(0, 0, 0), (0, 0), (1,), (1,)]
self.levels = []
for i in range(len(depths)):
path_drop = path_drops[sum(depths[:i]) : sum(depths[: i + 1])].tolist()
level = Level(
depth=depths[i],
num_heads=num_heads[i],
window_size=window_size[i],
keepdims=keepdims[i],
downsample=(i < len(depths) - 1),
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
dropout=drop_rate,
attention_dropout=attention_dropout,
path_drop=path_drop,
layer_scale=layer_scale,
name=f"levels_{i}",
)
self.levels.append(level)
self.norm = layers.LayerNormalization(axis=-1, epsilon=1e-05, name="norm")
self.pool = layers.GlobalAvgPool2D(name="pool")
self.head = layers.Dense(num_classes, name="head", activation=head_activation)
def build(self, input_shape):
super().build(input_shape)
self.built = True
def call(self, inputs, **kwargs):
x = self.patch_embed(inputs) # shape: (B, H, W, C)
x = self.pos_drop(x)
for level in self.levels:
x = level(x) # shape: (B, H_, W_, C_)
x = self.norm(x)
x = self.pool(x) # shape: (B, C__)
x = self.head(x)
return x
def build_graph(self, input_shape=(224, 224, 3)):
"""
ref: https://www.kaggle.com/code/ipythonx/tf-hybrid-efficientnet-swin-transformer-gradcam
"""
x = keras.Input(shape=input_shape)
return keras.Model(inputs=[x], outputs=self.call(x), name=self.name)
def summary(self, input_shape=(224, 224, 3)):
return self.build_graph(input_shape).summary()
建立模型
- 讓我們使用上面解釋的所有模組來建立一個完整的模型。我們將使用論文中提到的配置建立 GCViT-XXTiny 模型。
- 我們還將載入移植的官方預訓練權重,並嘗試進行一些預測。
# Model Configs
config = {
"window_size": (7, 7, 14, 7),
"embed_dim": 64,
"depths": (2, 2, 6, 2),
"num_heads": (2, 4, 8, 16),
"mlp_ratio": 3.0,
"path_drop": 0.2,
}
ckpt_link = (
"https://github.com/awsaf49/gcvit-tf/releases/download/v1.1.6/gcvitxxtiny.keras"
)
# Build Model
model = GCViT(**config)
inp = ops.array(np.random.uniform(size=(1, 224, 224, 3)))
out = model(inp)
# Load Weights
ckpt_path = keras.utils.get_file(ckpt_link.split("/")[-1], ckpt_link)
model.load_weights(ckpt_path)
# Summary
model.summary((224, 224, 3))
Downloading data from https://github.com/awsaf49/gcvit-tf/releases/download/v1.1.6/gcvitxxtiny.keras
48767519/48767519 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Model: "gc_vi_t"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, 224, 224, 3) │ 0 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ patch_embed (PatchEmbed) │ (None, 56, 56, 64) │ 45,632 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ pos_drop (Dropout) │ (None, 56, 56, 64) │ 0 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ levels_0 (Level) │ (None, 28, 28, 128) │ 180,964 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ levels_1 (Level) │ (None, 14, 14, 256) │ 688,456 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ levels_2 (Level) │ (None, 7, 7, 512) │ 5,170,608 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ levels_3 (Level) │ (None, 7, 7, 512) │ 5,395,744 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ norm (LayerNormalization) │ (None, 7, 7, 512) │ 1,024 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ pool (GlobalAveragePooling2D) │ (None, 512) │ 0 │ ├────────────────────────────────────┼───────────────────────────────┼─────────────┤ │ head (Dense) │ (None, 1000) │ 513,000 │ └────────────────────────────────────┴───────────────────────────────┴─────────────┘
Total params: 11,995,428 (45.76 MB)
Trainable params: 11,995,428 (45.76 MB)
Non-trainable params: 0 (0.00 B)
預訓練權重的健全性檢查
img = keras.applications.imagenet_utils.preprocess_input(
chelsea(), mode="torch"
) # Chelsea the cat
img = ops.image.resize(img, (224, 224))[None,] # resize & create batch
pred = model(img)
pred_dec = keras.applications.imagenet_utils.decode_predictions(pred)[0]
print("\n# Image:")
plt.figure(figsize=(6, 6))
plt.imshow(chelsea())
plt.show()
print()
print("# Prediction (Top 5):")
for i in range(5):
print("{:<12} : {:0.2f}".format(pred_dec[i][1], pred_dec[i][2]))
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
35363/35363 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
# Image:
![]()
# Prediction (Top 5):
Egyptian_cat : 0.72
tiger_cat : 0.04
tabby : 0.03
crossword_puzzle : 0.01
panpipe : 0.00
微調 GCViT 模型
在以下單元格中,我們將在包含 104 個類別的花卉資料集上微調 GCViT 模型。
配置
# Model
IMAGE_SIZE = (224, 224)
# Hyper Params
BATCH_SIZE = 32
EPOCHS = 5
# Dataset
CLASSES = [
"dandelion",
"daisy",
"tulips",
"sunflowers",
"roses",
] # don't change the order
# Other constants
MEAN = 255 * np.array([0.485, 0.456, 0.406], dtype="float32") # imagenet mean
STD = 255 * np.array([0.229, 0.224, 0.225], dtype="float32") # imagenet std
AUTO = tf.data.AUTOTUNE
資料載入器
def make_dataset(dataset: tf.data.Dataset, train: bool, image_size: int = IMAGE_SIZE):
def preprocess(image, label):
# for training, do augmentation
if train:
if tf.random.uniform(shape=[]) > 0.5:
image = tf.image.flip_left_right(image)
image = tf.image.resize(image, size=image_size, method="bicubic")
image = (image - MEAN) / STD # normalization
return image, label
if train:
dataset = dataset.shuffle(BATCH_SIZE * 10)
return dataset.map(preprocess, AUTO).batch(BATCH_SIZE).prefetch(AUTO)
花卉資料集
train_dataset, val_dataset = tfds.load(
"tf_flowers",
split=["train[:90%]", "train[90%:]"],
as_supervised=True,
try_gcs=False, # gcs_path is necessary for tpu,
)
train_dataset = make_dataset(train_dataset, True)
val_dataset = make_dataset(val_dataset, False)
Downloading and preparing dataset 218.21 MiB (download: 218.21 MiB, generated: 221.83 MiB, total: 440.05 MiB) to /root/tensorflow_datasets/tf_flowers/3.0.1...
Dl Completed...: 0%| | 0/5 [00:00<?, ? file/s]
Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/3.0.1. Subsequent calls will reuse this data.
重新建立花卉資料集的模型
# Re-Build Model
model = GCViT(**config, num_classes=104)
inp = ops.array(np.random.uniform(size=(1, 224, 224, 3)))
out = model(inp)
# Load Weights
ckpt_path = keras.utils.get_file(ckpt_link.split("/")[-1], ckpt_link)
model.load_weights(ckpt_path, skip_mismatch=True)
model.compile(
loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"]
)
/usr/local/lib/python3.10/dist-packages/keras/src/saving/saving_lib.py:269: UserWarning: A total of 1 objects could not be loaded. Example error message for object <Dense name=head, built=True>:
Layer 'head' expected 2 variables, but received 0 variables during loading. Expected: ['kernel', 'bias']
List of objects that could not be loaded:
[<Dense name=head, built=True>]
warnings.warn(msg)
訓練
history = model.fit(
train_dataset, validation_data=val_dataset, epochs=EPOCHS, verbose=1
)
Epoch 1/5
104/104 ━━━━━━━━━━━━━━━━━━━━ 153s 581ms/step - accuracy: 0.5140 - loss: 1.4615 - val_accuracy: 0.8828 - val_loss: 0.3485
Epoch 2/5
104/104 ━━━━━━━━━━━━━━━━━━━━ 7s 69ms/step - accuracy: 0.8775 - loss: 0.3437 - val_accuracy: 0.8828 - val_loss: 0.3508
Epoch 3/5
104/104 ━━━━━━━━━━━━━━━━━━━━ 7s 68ms/step - accuracy: 0.8937 - loss: 0.2918 - val_accuracy: 0.9019 - val_loss: 0.2953
Epoch 4/5
104/104 ━━━━━━━━━━━━━━━━━━━━ 7s 68ms/step - accuracy: 0.9232 - loss: 0.2397 - val_accuracy: 0.9183 - val_loss: 0.2212
Epoch 5/5
104/104 ━━━━━━━━━━━━━━━━━━━━ 7s 68ms/step - accuracy: 0.9456 - loss: 0.1645 - val_accuracy: 0.9210 - val_loss: 0.2897