使用對比預訓練與 SimCLR 進行半監督圖像分類
作者: András Béres
建立日期 2021/04/24
上次修改日期 2024/03/04
說明: 使用 SimCLR 進行對比預訓練,在 STL-10 資料集上進行半監督圖像分類。

簡介
半監督學習
半監督學習是一種機器學習範式,處理部分標記的資料集。當在現實世界中應用深度學習時,通常必須收集一個大型資料集才能使其良好運作。然而,雖然標記成本會隨著資料集大小線性增加(標記每個範例需要固定時間),但模型效能僅會隨著資料集大小次線性增加。這表示標記越來越多的樣本變得越來越不符合成本效益,而收集未標記資料通常很便宜,因為它通常可以大量取得。
半監督學習旨在透過僅需部分標記的資料集來解決此問題,並且透過利用未標記的範例進行學習來提高標籤效率。
在此範例中,我們將使用對比學習在 STL-10 半監督資料集上預訓練一個編碼器,完全不使用標籤,然後僅使用其標記的子集對其進行微調。
對比學習
在最高層次上,對比學習背後的主要思想是以自我監督的方式學習對圖像擴增不變的表示。此目標的一個問題是,它有一個微不足道的退化解:表示是常數,並且根本不依賴於輸入圖像的情況。
對比學習透過以下方式修改目標來避免此陷阱:它將同一圖像的擴增版本/視圖的表示拉近彼此(縮減正例),同時在表示空間中將不同的圖像推離彼此(對比負例)。
其中一種對比方法是 SimCLR,它基本上識別了優化此目標所需的核心元件,並且可以透過擴展此簡單方法來實現高性能。
另一種方法是 SimSiam(Keras 範例),它與 SimCLR 的主要區別在於,前者在其損失中不使用任何負例。因此,它不會明確阻止微不足道的解,而是透過架構設計隱式地避免它(在最後一層中應用使用預測器網路和批次正規化 (BatchNorm) 的不對稱編碼路徑)。
有關 SimCLR 的更多資訊,請查看官方 Google AI 部落格文章,有關視覺和語言中自我監督學習的概述,請查看此部落格文章。
設定
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
# Make sure we are able to handle large datasets
import resource
low, high = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (high, high))
import math
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import keras
from keras import ops
from keras import layers
超參數設定
# Dataset hyperparameters
unlabeled_dataset_size = 100000
labeled_dataset_size = 5000
image_channels = 3
# Algorithm hyperparameters
num_epochs = 20
batch_size = 525 # Corresponds to 200 steps per epoch
width = 128
temperature = 0.1
# Stronger augmentations for contrastive, weaker ones for supervised training
contrastive_augmentation = {"min_area": 0.25, "brightness": 0.6, "jitter": 0.2}
classification_augmentation = {
"min_area": 0.75,
"brightness": 0.3,
"jitter": 0.1,
}
資料集
在訓練期間,我們將同時載入一大批未標記的圖像以及一小批標記的圖像。
def prepare_dataset():
# Labeled and unlabeled samples are loaded synchronously
# with batch sizes selected accordingly
steps_per_epoch = (unlabeled_dataset_size + labeled_dataset_size) // batch_size
unlabeled_batch_size = unlabeled_dataset_size // steps_per_epoch
labeled_batch_size = labeled_dataset_size // steps_per_epoch
print(
f"batch size is {unlabeled_batch_size} (unlabeled) + {labeled_batch_size} (labeled)"
)
# Turning off shuffle to lower resource usage
unlabeled_train_dataset = (
tfds.load("stl10", split="unlabelled", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * unlabeled_batch_size)
.batch(unlabeled_batch_size)
)
labeled_train_dataset = (
tfds.load("stl10", split="train", as_supervised=True, shuffle_files=False)
.shuffle(buffer_size=10 * labeled_batch_size)
.batch(labeled_batch_size)
)
test_dataset = (
tfds.load("stl10", split="test", as_supervised=True)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# Labeled and unlabeled datasets are zipped together
train_dataset = tf.data.Dataset.zip(
(unlabeled_train_dataset, labeled_train_dataset)
).prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, labeled_train_dataset, test_dataset
# Load STL10 dataset
train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()
batch size is 500 (unlabeled) + 25 (labeled)
圖像擴增
對於對比學習,兩個最重要的圖像擴增如下
- 裁剪:強制模型以類似的方式編碼同一圖像的不同部分,我們使用 RandomTranslation 和 RandomZoom 層來實現。
- 色彩抖動:通過扭曲色彩直方圖,防止出現基於色彩直方圖的簡單解法。一個有原則的實現方式是在色彩空間中進行仿射變換。
在這個例子中,我們也使用了隨機水平翻轉。對於對比學習,我們應用了更強的數據增強,同時對於監督式分類則應用較弱的增強,以避免在少量標記範例上過度擬合。
我們將隨機色彩抖動實現為一個自訂預處理層。使用預處理層進行數據增強有以下兩個優點
- 數據增強將在 GPU 上批量運行,因此在 CPU 資源受限的環境(例如 Colab Notebook 或個人電腦)中,訓練不會受到數據管道的瓶頸限制。
- 部署更加容易,因為數據預處理管道被封裝在模型中,因此在部署時無需重新實作。
# Distorts the color distibutions of images
class RandomColorAffine(layers.Layer):
def __init__(self, brightness=0, jitter=0, **kwargs):
super().__init__(**kwargs)
self.seed_generator = keras.random.SeedGenerator(1337)
self.brightness = brightness
self.jitter = jitter
def get_config(self):
config = super().get_config()
config.update({"brightness": self.brightness, "jitter": self.jitter})
return config
def call(self, images, training=True):
if training:
batch_size = ops.shape(images)[0]
# Same for all colors
brightness_scales = 1 + keras.random.uniform(
(batch_size, 1, 1, 1),
minval=-self.brightness,
maxval=self.brightness,
seed=self.seed_generator,
)
# Different for all colors
jitter_matrices = keras.random.uniform(
(batch_size, 1, 3, 3),
minval=-self.jitter,
maxval=self.jitter,
seed=self.seed_generator,
)
color_transforms = (
ops.tile(ops.expand_dims(ops.eye(3), axis=0), (batch_size, 1, 1, 1))
* brightness_scales
+ jitter_matrices
)
images = ops.clip(ops.matmul(images, color_transforms), 0, 1)
return images
# Image augmentation module
def get_augmenter(min_area, brightness, jitter):
zoom_factor = 1.0 - math.sqrt(min_area)
return keras.Sequential(
[
layers.Rescaling(1 / 255),
layers.RandomFlip("horizontal"),
layers.RandomTranslation(zoom_factor / 2, zoom_factor / 2),
layers.RandomZoom((-zoom_factor, 0.0), (-zoom_factor, 0.0)),
RandomColorAffine(brightness, jitter),
]
)
def visualize_augmentations(num_images):
# Sample a batch from a dataset
images = next(iter(train_dataset))[0][0][:num_images]
# Apply augmentations
augmented_images = zip(
images,
get_augmenter(**classification_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
)
row_titles = [
"Original:",
"Weakly augmented:",
"Strongly augmented:",
"Strongly augmented:",
]
plt.figure(figsize=(num_images * 2.2, 4 * 2.2), dpi=100)
for column, image_row in enumerate(augmented_images):
for row, image in enumerate(image_row):
plt.subplot(4, num_images, row * num_images + column + 1)
plt.imshow(image)
if column == 0:
plt.title(row_titles[row], loc="left")
plt.axis("off")
plt.tight_layout()
visualize_augmentations(num_images=8)

編碼器架構
# Define the encoder architecture
def get_encoder():
return keras.Sequential(
[
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Flatten(),
layers.Dense(width, activation="relu"),
],
name="encoder",
)
監督式基準模型
使用隨機初始化訓練基準監督式模型。
# Baseline supervised training with random initialization
baseline_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
get_encoder(),
layers.Dense(10),
],
name="baseline_model",
)
baseline_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
baseline_history = baseline_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(baseline_history.history["val_acc"]) * 100
)
)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 9s 25ms/step - acc: 0.2031 - loss: 2.1576 - val_acc: 0.3234 - val_loss: 1.7719
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.3476 - loss: 1.7792 - val_acc: 0.4042 - val_loss: 1.5626
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4060 - loss: 1.6054 - val_acc: 0.4319 - val_loss: 1.4832
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4347 - loss: 1.5052 - val_acc: 0.4570 - val_loss: 1.4428
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.4600 - loss: 1.4546 - val_acc: 0.4765 - val_loss: 1.3977
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4754 - loss: 1.4015 - val_acc: 0.4740 - val_loss: 1.4082
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4901 - loss: 1.3589 - val_acc: 0.4761 - val_loss: 1.4061
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5110 - loss: 1.2793 - val_acc: 0.5247 - val_loss: 1.3026
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5298 - loss: 1.2765 - val_acc: 0.5138 - val_loss: 1.3286
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5514 - loss: 1.2078 - val_acc: 0.5543 - val_loss: 1.2227
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5520 - loss: 1.1851 - val_acc: 0.5446 - val_loss: 1.2709
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5851 - loss: 1.1368 - val_acc: 0.5725 - val_loss: 1.1944
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.5738 - loss: 1.1411 - val_acc: 0.5685 - val_loss: 1.1974
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 21ms/step - acc: 0.6078 - loss: 1.0308 - val_acc: 0.5899 - val_loss: 1.1769
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6284 - loss: 1.0386 - val_acc: 0.5863 - val_loss: 1.1742
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - acc: 0.6450 - loss: 0.9773 - val_acc: 0.5849 - val_loss: 1.1993
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6547 - loss: 0.9555 - val_acc: 0.5683 - val_loss: 1.2424
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6593 - loss: 0.9084 - val_acc: 0.5990 - val_loss: 1.1458
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6672 - loss: 0.9267 - val_acc: 0.5685 - val_loss: 1.2758
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6824 - loss: 0.8863 - val_acc: 0.5969 - val_loss: 1.2035
Maximal validation accuracy: 59.90%
用於對比預訓練的自我監督模型
我們使用對比損失在未標記的圖像上預訓練編碼器。一個非線性投射頭連接到編碼器的頂部,因為它可以提高編碼器表示的品質。
我們使用 InfoNCE/NT-Xent/N-pairs 損失,可以用以下方式解釋
- 我們將批次中的每個圖像視為它擁有自己的類別。
- 然後,對於每個「類別」,我們有兩個範例(一對增強視圖)。
- 每個視圖的表示都會與每個可能的配對(針對兩種增強版本)進行比較。
- 我們使用比較表示的溫度縮放餘弦相似性作為 logits。
- 最後,我們使用分類交叉熵作為「分類」損失。
以下兩個指標用於監控預訓練效能
- 對比準確度 (SimCLR 表 5):自我監督指標,表示圖像的表示與其不同增強版本的表示的相似度高於目前批次中任何其他圖像的表示的案例比例。即使在沒有標記範例的情況下,也可以使用自我監督指標進行超參數調整。
- 線性探測準確度:線性探測是評估自我監督分類器的一種常用指標。它被計算為在編碼器特徵之上訓練的邏輯回歸分類器的準確度。在我們的案例中,這是通過在凍結的編碼器之上訓練一個單一密集層來完成的。請注意,與傳統方法在預訓練階段之後訓練分類器相反,在這個例子中,我們在預訓練期間訓練它。這可能會稍微降低其準確度,但這樣我們可以在訓練期間監控其值,這有助於實驗和除錯。
另一個廣泛使用的監督指標是 KNN 準確度,它是基於編碼器的特徵訓練的 KNN 分類器的準確度,此範例中未實作。
# Define the contrastive model with model-subclassing
class ContrastiveModel(keras.Model):
def __init__(self):
super().__init__()
self.temperature = temperature
self.contrastive_augmenter = get_augmenter(**contrastive_augmentation)
self.classification_augmenter = get_augmenter(**classification_augmentation)
self.encoder = get_encoder()
# Non-linear MLP as projection head
self.projection_head = keras.Sequential(
[
keras.Input(shape=(width,)),
layers.Dense(width, activation="relu"),
layers.Dense(width),
],
name="projection_head",
)
# Single dense layer for linear probing
self.linear_probe = keras.Sequential(
[layers.Input(shape=(width,)), layers.Dense(10)],
name="linear_probe",
)
self.encoder.summary()
self.projection_head.summary()
self.linear_probe.summary()
def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):
super().compile(**kwargs)
self.contrastive_optimizer = contrastive_optimizer
self.probe_optimizer = probe_optimizer
# self.contrastive_loss will be defined as a method
self.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.contrastive_loss_tracker = keras.metrics.Mean(name="c_loss")
self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy(
name="c_acc"
)
self.probe_loss_tracker = keras.metrics.Mean(name="p_loss")
self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy(name="p_acc")
@property
def metrics(self):
return [
self.contrastive_loss_tracker,
self.contrastive_accuracy,
self.probe_loss_tracker,
self.probe_accuracy,
]
def contrastive_loss(self, projections_1, projections_2):
# InfoNCE loss (information noise-contrastive estimation)
# NT-Xent loss (normalized temperature-scaled cross entropy)
# Cosine similarity: the dot product of the l2-normalized feature vectors
projections_1 = ops.normalize(projections_1, axis=1)
projections_2 = ops.normalize(projections_2, axis=1)
similarities = (
ops.matmul(projections_1, ops.transpose(projections_2)) / self.temperature
)
# The similarity between the representations of two augmented views of the
# same image should be higher than their similarity with other views
batch_size = ops.shape(projections_1)[0]
contrastive_labels = ops.arange(batch_size)
self.contrastive_accuracy.update_state(contrastive_labels, similarities)
self.contrastive_accuracy.update_state(
contrastive_labels, ops.transpose(similarities)
)
# The temperature-scaled similarities are used as logits for cross-entropy
# a symmetrized version of the loss is used here
loss_1_2 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, similarities, from_logits=True
)
loss_2_1 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, ops.transpose(similarities), from_logits=True
)
return (loss_1_2 + loss_2_1) / 2
def train_step(self, data):
(unlabeled_images, _), (labeled_images, labels) = data
# Both labeled and unlabeled images are used, without labels
images = ops.concatenate((unlabeled_images, labeled_images), axis=0)
# Each image is augmented twice, differently
augmented_images_1 = self.contrastive_augmenter(images, training=True)
augmented_images_2 = self.contrastive_augmenter(images, training=True)
with tf.GradientTape() as tape:
features_1 = self.encoder(augmented_images_1, training=True)
features_2 = self.encoder(augmented_images_2, training=True)
# The representations are passed through a projection mlp
projections_1 = self.projection_head(features_1, training=True)
projections_2 = self.projection_head(features_2, training=True)
contrastive_loss = self.contrastive_loss(projections_1, projections_2)
gradients = tape.gradient(
contrastive_loss,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
self.contrastive_optimizer.apply_gradients(
zip(
gradients,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
)
self.contrastive_loss_tracker.update_state(contrastive_loss)
# Labels are only used in evalutation for an on-the-fly logistic regression
preprocessed_images = self.classification_augmenter(
labeled_images, training=True
)
with tf.GradientTape() as tape:
# the encoder is used in inference mode here to avoid regularization
# and updating the batch normalization paramers if they are used
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=True)
probe_loss = self.probe_loss(labels, class_logits)
gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)
self.probe_optimizer.apply_gradients(
zip(gradients, self.linear_probe.trainable_weights)
)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
labeled_images, labels = data
# For testing the components are used with a training=False flag
preprocessed_images = self.classification_augmenter(
labeled_images, training=False
)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=False)
probe_loss = self.probe_loss(labels, class_logits)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
# Only the probe metrics are logged at test time
return {m.name: m.result() for m in self.metrics[2:]}
# Contrastive pretraining
pretraining_model = ContrastiveModel()
pretraining_model.compile(
contrastive_optimizer=keras.optimizers.Adam(),
probe_optimizer=keras.optimizers.Adam(),
)
pretraining_history = pretraining_model.fit(
train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(pretraining_history.history["val_p_acc"]) * 100
)
)
Model: "encoder"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ conv2d_4 (Conv2D) │ ? │ 0 │ │ │ │ (unbuilt) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_5 (Conv2D) │ ? │ 0 │ │ │ │ (unbuilt) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_6 (Conv2D) │ ? │ 0 │ │ │ │ (unbuilt) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ conv2d_7 (Conv2D) │ ? │ 0 │ │ │ │ (unbuilt) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ flatten_1 (Flatten) │ ? │ 0 │ │ │ │ (unbuilt) │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense_2 (Dense) │ ? │ 0 │ │ │ │ (unbuilt) │ └─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 0 (0.00 B)
Trainable params: 0 (0.00 B)
Non-trainable params: 0 (0.00 B)
Model: "projection_head"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ dense_3 (Dense) │ (None, 128) │ 16,512 │ ├─────────────────────────────────┼───────────────────────────┼────────────┤ │ dense_4 (Dense) │ (None, 128) │ 16,512 │ └─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 33,024 (129.00 KB)
Trainable params: 33,024 (129.00 KB)
Non-trainable params: 0 (0.00 B)
Model: "linear_probe"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩ │ dense_5 (Dense) │ (None, 10) │ 1,290 │ └─────────────────────────────────┴───────────────────────────┴────────────┘
Total params: 1,290 (5.04 KB)
Trainable params: 1,290 (5.04 KB)
Non-trainable params: 0 (0.00 B)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 34s 134ms/step - c_acc: 0.0880 - c_loss: 5.2606 - p_acc: 0.1326 - p_loss: 2.2726 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.2579 - val_p_loss: 2.0671
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.2808 - c_loss: 3.6233 - p_acc: 0.2956 - p_loss: 2.0228 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3440 - val_p_loss: 1.9242
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.4097 - c_loss: 2.9369 - p_acc: 0.3671 - p_loss: 1.8674 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3876 - val_p_loss: 1.7757
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 142ms/step - c_acc: 0.4893 - c_loss: 2.5707 - p_acc: 0.3957 - p_loss: 1.7490 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.3960 - val_p_loss: 1.7002
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 136ms/step - c_acc: 0.5458 - c_loss: 2.3342 - p_acc: 0.4274 - p_loss: 1.6608 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4374 - val_p_loss: 1.6145
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.5949 - c_loss: 2.1179 - p_acc: 0.4410 - p_loss: 1.5812 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4444 - val_p_loss: 1.5439
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6273 - c_loss: 1.9861 - p_acc: 0.4633 - p_loss: 1.5076 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4695 - val_p_loss: 1.5056
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6566 - c_loss: 1.8668 - p_acc: 0.4817 - p_loss: 1.4601 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4790 - val_p_loss: 1.4566
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.6726 - c_loss: 1.7938 - p_acc: 0.4885 - p_loss: 1.4136 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.4933 - val_p_loss: 1.4163
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.6931 - c_loss: 1.7210 - p_acc: 0.4954 - p_loss: 1.3663 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5140 - val_p_loss: 1.3677
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 137ms/step - c_acc: 0.7055 - c_loss: 1.6619 - p_acc: 0.5210 - p_loss: 1.3376 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5155 - val_p_loss: 1.3573
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 30s 145ms/step - c_acc: 0.7215 - c_loss: 1.6112 - p_acc: 0.5264 - p_loss: 1.2920 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5232 - val_p_loss: 1.3337
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 31s 146ms/step - c_acc: 0.7279 - c_loss: 1.5749 - p_acc: 0.5388 - p_loss: 1.2570 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5217 - val_p_loss: 1.3155
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7435 - c_loss: 1.5196 - p_acc: 0.5505 - p_loss: 1.2507 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5460 - val_p_loss: 1.2640
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 40s 135ms/step - c_acc: 0.7477 - c_loss: 1.4979 - p_acc: 0.5653 - p_loss: 1.2188 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5594 - val_p_loss: 1.2351
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 139ms/step - c_acc: 0.7598 - c_loss: 1.4463 - p_acc: 0.5590 - p_loss: 1.1917 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5551 - val_p_loss: 1.2411
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7633 - c_loss: 1.4271 - p_acc: 0.5775 - p_loss: 1.1731 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5502 - val_p_loss: 1.2428
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7666 - c_loss: 1.4246 - p_acc: 0.5752 - p_loss: 1.1805 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5633 - val_p_loss: 1.2167
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 28s 135ms/step - c_acc: 0.7708 - c_loss: 1.3928 - p_acc: 0.5814 - p_loss: 1.1677 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5665 - val_p_loss: 1.2191
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 29s 140ms/step - c_acc: 0.7806 - c_loss: 1.3733 - p_acc: 0.5836 - p_loss: 1.1442 - val_c_acc: 0.0000e+00 - val_c_loss: 0.0000e+00 - val_p_acc: 0.5640 - val_p_loss: 1.2172
Maximal validation accuracy: 56.65%
預訓練編碼器的監督式微調
然後,我們通過在其頂部附加一個隨機初始化的完全連接分類層,在標記的範例上微調編碼器。
# Supervised finetuning of the pretrained encoder
finetuning_model = keras.Sequential(
[
get_augmenter(**classification_augmentation),
pretraining_model.encoder,
layers.Dense(10),
],
name="finetuning_model",
)
finetuning_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
finetuning_history = finetuning_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(finetuning_history.history["val_acc"]) * 100
)
)
Epoch 1/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 5s 18ms/step - acc: 0.2104 - loss: 2.0930 - val_acc: 0.4017 - val_loss: 1.5433
Epoch 2/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4037 - loss: 1.5791 - val_acc: 0.4544 - val_loss: 1.4250
Epoch 3/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.4639 - loss: 1.4161 - val_acc: 0.5266 - val_loss: 1.2958
Epoch 4/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5438 - loss: 1.2686 - val_acc: 0.5655 - val_loss: 1.1711
Epoch 5/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.5678 - loss: 1.1746 - val_acc: 0.5775 - val_loss: 1.1670
Epoch 6/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6096 - loss: 1.1071 - val_acc: 0.6034 - val_loss: 1.1400
Epoch 7/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6242 - loss: 1.0413 - val_acc: 0.6235 - val_loss: 1.0756
Epoch 8/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6284 - loss: 1.0264 - val_acc: 0.6030 - val_loss: 1.1048
Epoch 9/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6491 - loss: 0.9706 - val_acc: 0.5770 - val_loss: 1.2818
Epoch 10/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.6754 - loss: 0.9104 - val_acc: 0.6119 - val_loss: 1.1087
Epoch 11/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 20ms/step - acc: 0.6620 - loss: 0.8855 - val_acc: 0.6323 - val_loss: 1.0526
Epoch 12/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 19ms/step - acc: 0.7060 - loss: 0.8179 - val_acc: 0.6406 - val_loss: 1.0565
Epoch 13/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7252 - loss: 0.7796 - val_acc: 0.6135 - val_loss: 1.1273
Epoch 14/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7176 - loss: 0.7935 - val_acc: 0.6292 - val_loss: 1.1028
Epoch 15/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7322 - loss: 0.7471 - val_acc: 0.6266 - val_loss: 1.1313
Epoch 16/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7400 - loss: 0.7218 - val_acc: 0.6332 - val_loss: 1.1064
Epoch 17/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7490 - loss: 0.6968 - val_acc: 0.6532 - val_loss: 1.0112
Epoch 18/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7491 - loss: 0.6879 - val_acc: 0.6403 - val_loss: 1.1083
Epoch 19/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 4s 17ms/step - acc: 0.7802 - loss: 0.6504 - val_acc: 0.6479 - val_loss: 1.0548
Epoch 20/20
200/200 ━━━━━━━━━━━━━━━━━━━━ 3s 17ms/step - acc: 0.7800 - loss: 0.6234 - val_acc: 0.6409 - val_loss: 1.0998
Maximal validation accuracy: 65.32%
與基準的比較
# The classification accuracies of the baseline and the pretraining + finetuning process:
def plot_training_curves(pretraining_history, finetuning_history, baseline_history):
for metric_key, metric_name in zip(["acc", "loss"], ["accuracy", "loss"]):
plt.figure(figsize=(8, 5), dpi=100)
plt.plot(
baseline_history.history[f"val_{metric_key}"],
label="supervised baseline",
)
plt.plot(
pretraining_history.history[f"val_p_{metric_key}"],
label="self-supervised pretraining",
)
plt.plot(
finetuning_history.history[f"val_{metric_key}"],
label="supervised finetuning",
)
plt.legend()
plt.title(f"Classification {metric_name} during training")
plt.xlabel("epochs")
plt.ylabel(f"validation {metric_name}")
plot_training_curves(pretraining_history, finetuning_history, baseline_history)
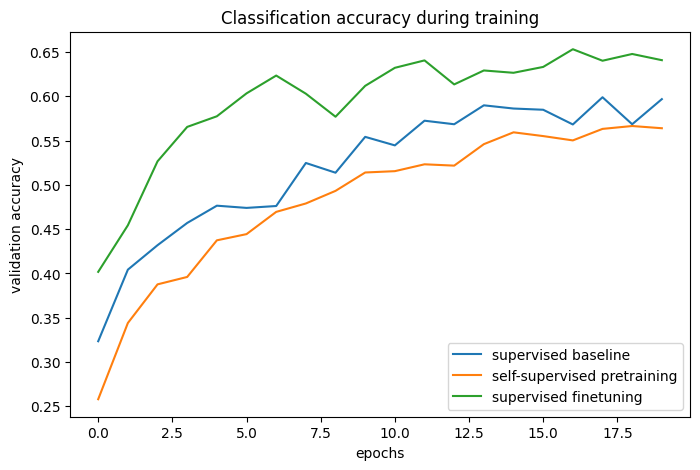
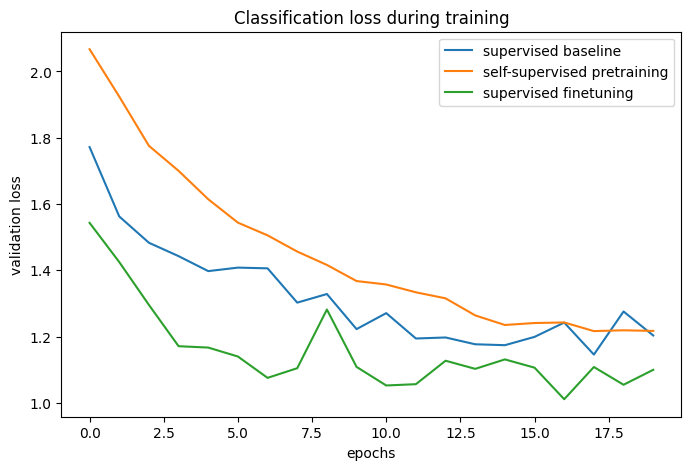
通過比較訓練曲線,我們可以發現,當使用對比預訓練時,可以達到更高的驗證準確度,並具有更低的驗證損失,這表示預訓練網路在僅看到少量標記範例時能夠更好地泛化。
進一步改進
架構
原始論文中的實驗表明,增加模型的寬度和深度可以比監督式學習更快地提高效能。此外,使用 ResNet-50 編碼器在文獻中非常常見。但是請記住,更強大的模型不僅會增加訓練時間,還會需要更多的記憶體,並限制您可以使用的最大批次大小。
據報導 指出,使用 BatchNorm 層有時會降低效能,因為它會在樣本之間引入批次內依賴性,這就是我在此範例中沒有使用它們的原因。然而,在我的實驗中,使用 BatchNorm,特別是在投射頭中,可以提高效能。
超參數
此範例中使用的超參數已針對此任務和架構進行手動調整。因此,在不更改它們的情況下,從進一步的超參數調整中只能獲得邊際收益。
但是,對於不同的任務或模型架構,這些都需要調整,因此以下是我對最重要的參數的註解
- 批次大小:由於目標可以解釋為對一批圖像的分類(粗略地說),因此批次大小實際上是比平常更重要的超參數。越大越好。
- 溫度:溫度定義了交叉熵損失中使用的 softmax 分佈的「軟度」,並且是一個重要的超參數。較低的值通常會導致更高的對比準確度。最近的一個技巧(在 ALIGN 中)是也學習溫度的值(可以通過將其定義為 tf.Variable 並對其應用梯度來完成)。即使這提供了一個良好的基準值,但在我的實驗中,學習的溫度略低於最佳值,因為它是相對於對比損失進行優化的,而對比損失並不是表示品質的完美指標。
- 圖像增強強度:在預訓練期間,較強的增強會增加任務的難度,但是,在某個點之後,過強的增強會降低效能。在微調期間,較強的增強會減少過度擬合,而在我的經驗中,過強的增強會降低預訓練帶來的效能增益。整個數據增強管道可以看作是該演算法的一個重要超參數,Keras 中其他自訂圖像增強層的實現可以在 此儲存庫中找到。
- 學習率排程:此處使用恆定排程,但在文獻中使用 餘弦衰減排程是很常見的,它可以進一步提高效能。
- 優化器:此範例中使用 Adam,因為它以預設參數提供了良好的效能。帶動量的 SGD 需要更多的調整,但是它可以稍微提高效能。
相關研究
其他實例級(圖像級)對比學習方法
- MoCo (v2, v3):也使用動量編碼器,其權重是目標編碼器的指數移動平均值
- SwAV:使用叢集而不是成對比較
- BarlowTwins:使用基於交叉相關性的目標而不是成對比較
MoCo 和 BarlowTwins 的 Keras 實作可以在 此儲存庫中找到,其中包含一個 Colab Notebook。
還有一系列新的研究,它們優化類似的目標,但不使用任何負樣本
根據我的經驗,這些方法更為脆弱(它們可能會崩潰為恆定的表示,我無法使用此編碼器架構使它們正常工作)。即使它們通常更依賴於 模型 架構,它們也可以在較小的批次大小中提高效能。
您可以使用 Hugging Face Hub 上託管的已訓練模型,並在 Hugging Face Spaces 上試用演示。