在 KerasHub 中體驗「Segment Anything」!
作者:Tirth Patel、Ian Stenbit、Divyashree Sreepathihalli
建立日期 2024/10/1
最後修改日期 2024/10/1
說明:在 KerasHub 中使用文字、方框和點提示來分割任何物件。

概觀
「Segment Anything Model (SAM)」可以根據點或方框等輸入提示產生高品質的物件遮罩,並且可以用於產生圖像中所有物件的遮罩。它已經在一個包含 1,100 萬張圖像和 11 億個遮罩的資料集上進行了訓練,並且在各種分割任務上都具有強大的零樣本學習效能。
在本指南中,我們將展示如何使用 KerasHub 對「Segment Anything Model」的實作,並展示 TensorFlow 和 JAX 的效能提升有多麼強大。
首先,讓我們取得所有必要的相依性和我們展示範例所需的圖像。
!!pip install -Uq git+https://github.com/keras-team/keras-hub.git
!!pip install -Uq keras
!!wget -q https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/truck.jpg
[]
[]
選擇您的後端
使用 Keras 3,您可以選擇使用您最喜歡的後端!
import os
os.environ["KERAS_BACKEND"] = "jax"
import timeit
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import ops
import keras_hub
輔助函式
讓我們定義一些輔助函數,用於可視化圖像、提示和分割結果。
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(
pos_points[:, 0],
pos_points[:, 1],
color="green",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
ax.scatter(
neg_points[:, 0],
neg_points[:, 1],
color="red",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
def show_box(box, ax):
box = box.reshape(-1)
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(
plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2)
)
def inference_resizing(image, pad=True):
# Compute Preprocess Shape
image = ops.cast(image, dtype="float32")
old_h, old_w = image.shape[0], image.shape[1]
scale = 1024 * 1.0 / max(old_h, old_w)
new_h = old_h * scale
new_w = old_w * scale
preprocess_shape = int(new_h + 0.5), int(new_w + 0.5)
# Resize the image
image = ops.image.resize(image[None, ...], preprocess_shape)[0]
# Pad the shorter side
if pad:
pixel_mean = ops.array([123.675, 116.28, 103.53])
pixel_std = ops.array([58.395, 57.12, 57.375])
image = (image - pixel_mean) / pixel_std
h, w = image.shape[0], image.shape[1]
pad_h = 1024 - h
pad_w = 1024 - w
image = ops.pad(image, [(0, pad_h), (0, pad_w), (0, 0)])
# KerasHub now rescales the images and normalizes them.
# Just unnormalize such that when KerasHub normalizes them
# again, the padded values map to 0.
image = image * pixel_std + pixel_mean
return image
取得預先訓練的 SAM 模型
我們可以使用 KerasHub 的 from_preset 工廠方法來初始化一個經過訓練的 SAM 模型。在這裡,我們使用在 SA-1B 資料集上訓練的巨大 ViT 骨幹網路 (sam_huge_sa1b) 來獲得高品質的分割遮罩。您也可以使用 sam_large_sa1b 或 sam_base_sa1b 來獲得更好的效能(但會降低分割遮罩的品質)。
model = keras_hub.models.SAMImageSegmenter.from_preset("sam_huge_sa1b")
Downloading from https://www.kaggle.com/api/v1/models/kerashub/sam/keras/sam_huge_sa1b/2/download/config.json...
100%|████████████████████████████████████████████████████| 3.06k/3.06k [00:00<00:00, 6.08MB/s]
Downloading from https://www.kaggle.com/api/v1/models/kerashub/sam/keras/sam_huge_sa1b/2/download/task.json...
100%|████████████████████████████████████████████████████| 5.76k/5.76k [00:00<00:00, 11.0MB/s]
Downloading from https://www.kaggle.com/api/v1/models/kerashub/sam/keras/sam_huge_sa1b/2/download/task.weights.h5...
100%|████████████████████████████████████████████████████| 2.39G/2.39G [00:26<00:00, 95.7MB/s]
Downloading from https://www.kaggle.com/api/v1/models/kerashub/sam/keras/sam_huge_sa1b/2/download/model.weights.h5...
100%|████████████████████████████████████████████████████| 2.39G/2.39G [00:32<00:00, 79.7MB/s]
瞭解提示
Segment Anything 允許使用點、框和遮罩來提示圖像
- 點提示是最基本的:模型會嘗試根據圖像上的點來猜測物件。該點可以是前景點(即所需的分割遮罩包含該點)或背景點(即該點位於所需遮罩之外)。
- 另一種提示模型的方法是使用框。給定一個邊界框,模型會嘗試分割其中包含的物件。
- 最後,模型也可以使用遮罩本身來提示。例如,這對於細化先前預測或已知的分割遮罩的邊界很有用。
使模型非常強大的原因是能夠組合上述提示。點、框和遮罩提示可以以幾種不同的方式組合,以獲得最佳結果。
讓我們看看在 KerasHub 中將這些提示傳遞給 Segment Anything 模型的語義。SAM 模型的輸入是一個包含以下鍵值的字典
"images":要分割的圖像批次。形狀必須為(B, 1024, 1024, 3)。"points":點提示的批次。每個點都是從圖像左上角開始的(x, y)坐標。換句話說,每個點的形式都是(r, c),其中r和c是圖像中像素的行和列。形狀必須為(B, N, 2)。"labels":給定點的標籤批次。1代表前景點,0代表背景點。形狀必須為(B, N)。"boxes":框的批次。請注意,模型每個批次只接受一個框。因此,預期的形狀為(B, 1, 2, 2)。每個框都是 2 個點的集合:框的左上角和右下角。這裡的點遵循與點提示相同的語義。這裡第二個維度中的1表示框提示的存在。如果缺少框提示,則必須傳遞形狀為(B, 0, 2, 2)的佔位符輸入。"masks":遮罩的批次。就像框提示一樣,每個圖像只允許一個遮罩提示。如果存在遮罩提示,則輸入遮罩的形狀必須為(B, 1, 256, 256, 1),如果缺少遮罩提示,則為(B, 0, 256, 256, 1)。
僅當直接呼叫模型(即 model(...))時才需要佔位符提示。當呼叫 predict 方法時,可以從輸入字典中省略缺少的提示。
點提示
首先,讓我們使用點提示來分割圖像。我們載入圖像並將其調整為 (1024, 1024) 的形狀,這是預先訓練的 SAM 模型預期的圖像大小。
# Load our image
image = np.array(keras.utils.load_img("truck.jpg"))
image = inference_resizing(image)
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
plt.axis("on")
plt.show()

接下來,我們將定義要分割的物件上的點。讓我們嘗試分割坐標為 (284, 213) 的卡車窗格。
# Define the input point prompt
input_point = np.array([[284, 213.5]])
input_label = np.array([1])
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_points(input_point, input_label, plt.gca())
plt.axis("on")
plt.show()

現在讓我們呼叫模型的 predict 方法來取得分割遮罩。
**注意**:我們不直接呼叫模型(model(...)),因為這樣做需要佔位符提示。缺少的提示會由預測方法自動處理,因此我們改為呼叫它。此外,當不存在框提示時,點和標籤需要分別填充零點提示和 -1 標籤提示。下面的儲存格演示了這是如何運作的。
outputs = model.predict(
{
"images": image[np.newaxis, ...],
"points": np.concatenate(
[input_point[np.newaxis, ...], np.zeros((1, 1, 2))], axis=1
),
"labels": np.concatenate(
[input_label[np.newaxis, ...], np.full((1, 1), fill_value=-1)], axis=1
),
}
)
Could not load symbol cuFuncGetName. Error: /usr/lib64-nvidia/libcuda.so.1: undefined symbol: cuFuncGetName
1/1 ━━━━━━━━━━━━━━━━━━━━ 24s 24s/step
SegmentAnythingModel.predict 會返回兩個輸出。首先是形狀為 (1, 4, 256, 256) 的 logits(分割遮罩),另一個是每個預測遮罩的 IoU 信心分數(形狀為 (1, 4))。預先訓練的 SAM 模型會預測四個遮罩:第一個是模型針對給定提示所能想到的最佳遮罩,另外三個是替代遮罩,可在最佳預測未包含所需物件時使用。使用者可以選擇他們喜歡的任何遮罩。
讓我們將模型返回的遮罩視覺化!
# Resize the mask to our image shape i.e. (1024, 1024)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
# Convert the logits to a numpy array
# and convert the logits to a boolean mask
mask = ops.convert_to_numpy(mask) > 0.0
iou_score = ops.convert_to_numpy(outputs["iou_pred"][0][0])
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"IoU Score: {iou_score:.3f}", fontsize=18)
plt.axis("off")
plt.show()

如預期所示,模型返回了卡車窗格的分割遮罩。但是,我們的點提示也可以表示一系列其他事物。例如,包含我們點的另一個可能的遮罩只是窗格的右側或整個卡車。
讓我們也將模型預測的其他遮罩視覺化。
fig, ax = plt.subplots(1, 3, figsize=(20, 60))
masks, scores = outputs["masks"][0][1:], outputs["iou_pred"][0][1:]
for i, (mask, score) in enumerate(zip(masks, scores)):
mask = inference_resizing(mask[..., None], pad=False)[..., 0]
mask, score = map(ops.convert_to_numpy, (mask, score))
mask = 1 * (mask > 0.0)
ax[i].imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, ax[i])
show_points(input_point, input_label, ax[i])
ax[i].set_title(f"Mask {i+1}, Score: {score:.3f}", fontsize=12)
ax[i].axis("off")
plt.show()

太棒了!SAM 能夠捕捉到我們點提示的模糊性,並且還返回了其他可能的分割遮罩。
方框提示
現在,讓我們看看如何使用方框提示模型。方框使用兩個點指定,即邊界框左上角和右下角的 xyxy 格式。讓我們使用卡車左前輪胎周圍的邊界框提示模型。
# Let's specify the box
input_box = np.array([[240, 340], [400, 500]])
outputs = model.predict(
{"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis, np.newaxis, ...]}
)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_box(input_box, plt.gca())
plt.axis("off")
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 10s 10s/step

砰!模型完美地分割出我們邊界框中的左前輪胎。
組合提示
為了發揮模型的真正潛力,讓我們結合方框和點提示,看看模型會做什麼。
# Let's specify the box
input_box = np.array([[240, 340], [400, 500]])
# Let's specify the point and mark it background
input_point = np.array([[325, 425]])
input_label = np.array([0])
outputs = model.predict(
{
"images": image[np.newaxis, ...],
"points": input_point[np.newaxis, ...],
"labels": input_label[np.newaxis, ...],
"boxes": input_box[np.newaxis, np.newaxis, ...],
}
)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis("off")
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 14s 14s/step

瞧!模型了解到我們想要從遮罩中排除的物件是輪胎的輪輞。
文字提示
最後,讓我們看看如何將文字提示與 KerasHub 的 SegmentAnythingModel 一起使用。
對於此演示,我們將使用官方 Grounding DINO 模型。Grounding DINO 是一個模型,它將 (圖像,文字) 對作為輸入,並在 文字 描述的 圖像 中的物件周圍生成一個邊界框。您可以參考論文以獲取有關模型實現的更多詳細資訊。
對於演示的這一部分,我們需要從源安裝 groundingdino 套件
pip install -U git+https://github.com/IDEA-Research/GroundingDINO.git
然後,我們可以安裝預先訓練的模型的權重和配置
!!pip install -U git+https://github.com/IDEA-Research/GroundingDINO.git
!!wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
!!wget -q https://raw.githubusercontent.com/IDEA-Research/GroundingDINO/v0.1.0-alpha2/groundingdino/config/GroundingDINO_SwinT_OGC.py
from groundingdino.util.inference import Model as GroundingDINO
CONFIG_PATH = "GroundingDINO_SwinT_OGC.py"
WEIGHTS_PATH = "groundingdino_swint_ogc.pth"
grounding_dino = GroundingDINO(CONFIG_PATH, WEIGHTS_PATH)
['Collecting git+https://github.com/IDEA-Research/GroundingDINO.git',
' Cloning https://github.com/IDEA-Research/GroundingDINO.git to /tmp/pip-req-build-m_hhz04_',
' Running command git clone --filter=blob:none --quiet https://github.com/IDEA-Research/GroundingDINO.git /tmp/pip-req-build-m_hhz04_',
' Resolved https://github.com/IDEA-Research/GroundingDINO.git to commit 856dde20aee659246248e20734ef9ba5214f5e44',
' Preparing metadata (setup.py) ... \x1b[?25l\x1b[?25hdone',
'Requirement already satisfied: torch in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (2.4.1+cu121)',
'Requirement already satisfied: torchvision in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (0.19.1+cu121)',
'Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (4.44.2)',
'Collecting addict (from groundingdino==0.1.0)',
' Downloading addict-2.4.0-py3-none-any.whl.metadata (1.0 kB)',
'Collecting yapf (from groundingdino==0.1.0)',
' Downloading yapf-0.40.2-py3-none-any.whl.metadata (45 kB)',
'\x1b[?25l \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m0.0/45.4 kB\x1b[0m \x1b[31m?\x1b[0m eta \x1b[36m-:--:--\x1b[0m',
'\x1b[2K \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m45.4/45.4 kB\x1b[0m \x1b[31m1.8 MB/s\x1b[0m eta \x1b[36m0:00:00\x1b[0m',
'\x1b[?25hCollecting timm (from groundingdino==0.1.0)',
' Downloading timm-1.0.9-py3-none-any.whl.metadata (42 kB)',
'\x1b[?25l \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m0.0/42.4 kB\x1b[0m \x1b[31m?\x1b[0m eta \x1b[36m-:--:--\x1b[0m',
'\x1b[2K \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m42.4/42.4 kB\x1b[0m \x1b[31m1.8 MB/s\x1b[0m eta \x1b[36m0:00:00\x1b[0m',
'\x1b[?25hRequirement already satisfied: numpy in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (1.26.4)',
'Requirement already satisfied: opencv-python in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (4.10.0.84)',
'Collecting supervision>=0.22.0 (from groundingdino==0.1.0)',
' Downloading supervision-0.23.0-py3-none-any.whl.metadata (14 kB)',
'Requirement already satisfied: pycocotools in /usr/local/lib/python3.10/dist-packages (from groundingdino==0.1.0) (2.0.8)',
'Requirement already satisfied: defusedxml<0.8.0,>=0.7.1 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (0.7.1)',
'Requirement already satisfied: matplotlib>=3.6.0 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (3.7.1)',
'Requirement already satisfied: opencv-python-headless>=4.5.5.64 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (4.10.0.84)',
'Requirement already satisfied: pillow>=9.4 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (10.4.0)',
'Requirement already satisfied: pyyaml>=5.3 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (6.0.2)',
'Requirement already satisfied: scipy<2.0.0,>=1.10.0 in /usr/local/lib/python3.10/dist-packages (from supervision>=0.22.0->groundingdino==0.1.0) (1.13.1)',
'Requirement already satisfied: huggingface_hub in /usr/local/lib/python3.10/dist-packages (from timm->groundingdino==0.1.0) (0.24.7)',
'Requirement already satisfied: safetensors in /usr/local/lib/python3.10/dist-packages (from timm->groundingdino==0.1.0) (0.4.5)',
'Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (3.16.1)',
'Requirement already satisfied: typing-extensions>=4.8.0 in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (4.12.2)',
'Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (1.13.3)',
'Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (3.3)',
'Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (3.1.4)',
'Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch->groundingdino==0.1.0) (2024.6.1)',
'Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers->groundingdino==0.1.0) (24.1)',
'Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers->groundingdino==0.1.0) (2024.9.11)',
'Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers->groundingdino==0.1.0) (2.32.3)',
'Requirement already satisfied: tokenizers<0.20,>=0.19 in /usr/local/lib/python3.10/dist-packages (from transformers->groundingdino==0.1.0) (0.19.1)',
'Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers->groundingdino==0.1.0) (4.66.5)',
'Requirement already satisfied: importlib-metadata>=6.6.0 in /usr/local/lib/python3.10/dist-packages (from yapf->groundingdino==0.1.0) (8.4.0)',
'Requirement already satisfied: platformdirs>=3.5.1 in /usr/local/lib/python3.10/dist-packages (from yapf->groundingdino==0.1.0) (4.3.6)',
'Requirement already satisfied: tomli>=2.0.1 in /usr/local/lib/python3.10/dist-packages (from yapf->groundingdino==0.1.0) (2.0.1)',
'Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.10/dist-packages (from importlib-metadata>=6.6.0->yapf->groundingdino==0.1.0) (3.20.2)',
'Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (1.3.0)',
'Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (0.12.1)',
'Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (4.54.1)',
'Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (1.4.7)',
'Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (3.1.4)',
'Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (2.8.2)',
'Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch->groundingdino==0.1.0) (2.1.5)',
'Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->transformers->groundingdino==0.1.0) (3.3.2)',
'Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers->groundingdino==0.1.0) (3.10)',
'Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers->groundingdino==0.1.0) (2.2.3)',
'Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers->groundingdino==0.1.0) (2024.8.30)',
'Requirement already satisfied: mpmath<1.4,>=1.1.0 in /usr/local/lib/python3.10/dist-packages (from sympy->torch->groundingdino==0.1.0) (1.3.0)',
'Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib>=3.6.0->supervision>=0.22.0->groundingdino==0.1.0) (1.16.0)',
'Downloading supervision-0.23.0-py3-none-any.whl (151 kB)',
'\x1b[?25l \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m0.0/151.5 kB\x1b[0m \x1b[31m?\x1b[0m eta \x1b[36m-:--:--\x1b[0m',
'\x1b[2K \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m151.5/151.5 kB\x1b[0m \x1b[31m6.0 MB/s\x1b[0m eta \x1b[36m0:00:00\x1b[0m',
'\x1b[?25hDownloading addict-2.4.0-py3-none-any.whl (3.8 kB)',
'Downloading timm-1.0.9-py3-none-any.whl (2.3 MB)',
'\x1b[?25l \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m0.0/2.3 MB\x1b[0m \x1b[31m?\x1b[0m eta \x1b[36m-:--:--\x1b[0m',
'\x1b[2K \x1b[91m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m\x1b[90m╺\x1b[0m\x1b[90m━━━━━━━\x1b[0m \x1b[32m1.9/2.3 MB\x1b[0m \x1b[31m55.9 MB/s\x1b[0m eta \x1b[36m0:00:01\x1b[0m',
'\x1b[2K \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m2.3/2.3 MB\x1b[0m \x1b[31m42.4 MB/s\x1b[0m eta \x1b[36m0:00:00\x1b[0m',
'\x1b[?25hDownloading yapf-0.40.2-py3-none-any.whl (254 kB)',
'\x1b[?25l \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m0.0/254.7 kB\x1b[0m \x1b[31m?\x1b[0m eta \x1b[36m-:--:--\x1b[0m',
'\x1b[2K \x1b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\x1b[0m \x1b[32m254.7/254.7 kB\x1b[0m \x1b[31m18.3 MB/s\x1b[0m eta \x1b[36m0:00:00\x1b[0m',
'\x1b[?25hBuilding wheels for collected packages: groundingdino',
' Building wheel for groundingdino (setup.py) ... \x1b[?25l\x1b[?25hdone',
' Created wheel for groundingdino: filename=groundingdino-0.1.0-cp310-cp310-linux_x86_64.whl size=3038498 sha256=1e7306dfa5ebd4bebb340bfe814e13026800708bbc0223d37ae8963e90145fb2',
' Stored in directory: /tmp/pip-ephem-wheel-cache-multbs74/wheels/6b/06/d7/b57f601a4df56af41d262a5b1b496359b13c323bf5ef0434b2',
'Successfully built groundingdino',
'Installing collected packages: addict, yapf, supervision, timm, groundingdino',
'Successfully installed addict-2.4.0 groundingdino-0.1.0 supervision-0.23.0 timm-1.0.9 yapf-0.40.2']
[]
UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3609.)
final text_encoder_type: bert-base-uncased
UserWarning:
Error while fetching `HF_TOKEN` secret value from your vault: 'Requesting secret HF_TOKEN timed out. Secrets can only be fetched when running from the Colab UI.'.
You are not authenticated with the Hugging Face Hub in this notebook.
If the error persists, please let us know by opening an issue on GitHub (https://github.com/huggingface/huggingface_hub/issues/new).
tokenizer_config.json: 0%| | 0.00/48.0 [00:00<?, ?B/s]
config.json: 0%| | 0.00/570 [00:00<?, ?B/s]
vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]
FutureWarning: `clean_up_tokenization_spaces` was not set. It will be set to `True` by default. This behavior will be depracted in transformers v4.45, and will be then set to `False` by default. For more details check this issue: https://github.com/huggingface/transformers/issues/31884
model.safetensors: 0%| | 0.00/440M [00:00<?, ?B/s]
FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
讓我們為這部分加載一張狗的圖片!
filepath = keras.utils.get_file(
origin="https://storage.googleapis.com/keras-cv/test-images/mountain-dog.jpeg"
)
image = np.array(keras.utils.load_img(filepath))
image = ops.convert_to_numpy(inference_resizing(image))
plt.figure(figsize=(10, 10))
plt.imshow(image / 255.0)
plt.axis("on")
plt.show()
Downloading data from https://storage.googleapis.com/keras-cv/test-images/mountain-dog.jpeg
1236492/1236492 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
我們首先使用 Grounding DINO 模型預測我們要分割的物件的邊界框。然後,我們使用邊界框提示 SAM 模型以獲取分割遮罩。
讓我們嘗試分割出狗的背帶。更改下面的圖像和文字,以使用圖像中的文字分割您想要的任何內容!
# Let's predict the bounding box for the harness of the dog
boxes = grounding_dino.predict_with_caption(image.astype(np.uint8), "harness")
boxes = np.array(boxes[0].xyxy)
outputs = model.predict(
{
"images": np.repeat(image[np.newaxis, ...], boxes.shape[0], axis=0),
"boxes": boxes.reshape(-1, 1, 2, 2),
},
batch_size=1,
)
FutureWarning: The `device` argument is deprecated and will be removed in v5 of Transformers.
UserWarning: torch.utils.checkpoint: the use_reentrant parameter should be passed explicitly. In version 2.4 we will raise an exception if use_reentrant is not passed. use_reentrant=False is recommended, but if you need to preserve the current default behavior, you can pass use_reentrant=True. Refer to docs for more details on the differences between the two variants.
UserWarning: None of the inputs have requires_grad=True. Gradients will be None
FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
1/1 ━━━━━━━━━━━━━━━━━━━━ 10s 10s/step
就是这样!我們使用 Gounding DINO + SAM 的組合獲得了文字提示的分割遮罩!這是一種非常強大的技術,可以組合不同的模型來擴展應用範圍!
讓我們將結果視覺化。
plt.figure(figsize=(10, 10))
plt.imshow(image / 255.0)
for mask in outputs["masks"]:
mask = inference_resizing(mask[0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
show_mask(mask, plt.gca())
show_box(boxes, plt.gca())
plt.axis("off")
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

優化 SAM
您可以使用 mixed_float16 或 bfloat16 dtype 策略以相對較低的精度損失獲得巨大的速度提升和內存優化。
# Load our image
image = np.array(keras.utils.load_img("truck.jpg"))
image = inference_resizing(image)
# Specify the prompt
input_box = np.array([[240, 340], [400, 500]])
# Let's first see how fast the model is with float32 dtype
time_taken = timeit.repeat(
'model.predict({"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis, np.newaxis, ...]}, verbose=False)',
repeat=3,
number=3,
globals=globals(),
)
print(f"Time taken with float32 dtype: {min(time_taken) / 3:.10f}s")
# Set the dtype policy in Keras
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_hub.models.SAMImageSegmenter.from_preset("sam_huge_sa1b")
time_taken = timeit.repeat(
'model.predict({"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis,np.newaxis, ...]}, verbose=False)',
repeat=3,
number=3,
globals=globals(),
)
print(f"Time taken with float16 dtype: {min(time_taken) / 3:.10f}s")
Time taken with float32 dtype: 0.2298811787s
UserWarning: Skipping variable loading for optimizer 'loss_scale_optimizer', because it has 4 variables whereas the saved optimizer has 2 variables.
UserWarning: Skipping variable loading for optimizer 'adam', because it has 2 variables whereas the saved optimizer has 0 variables.
Time taken with float16 dtype: 0.2068303013s
以下是 KerasHub 實現與原始 PyTorch 實現的比較!
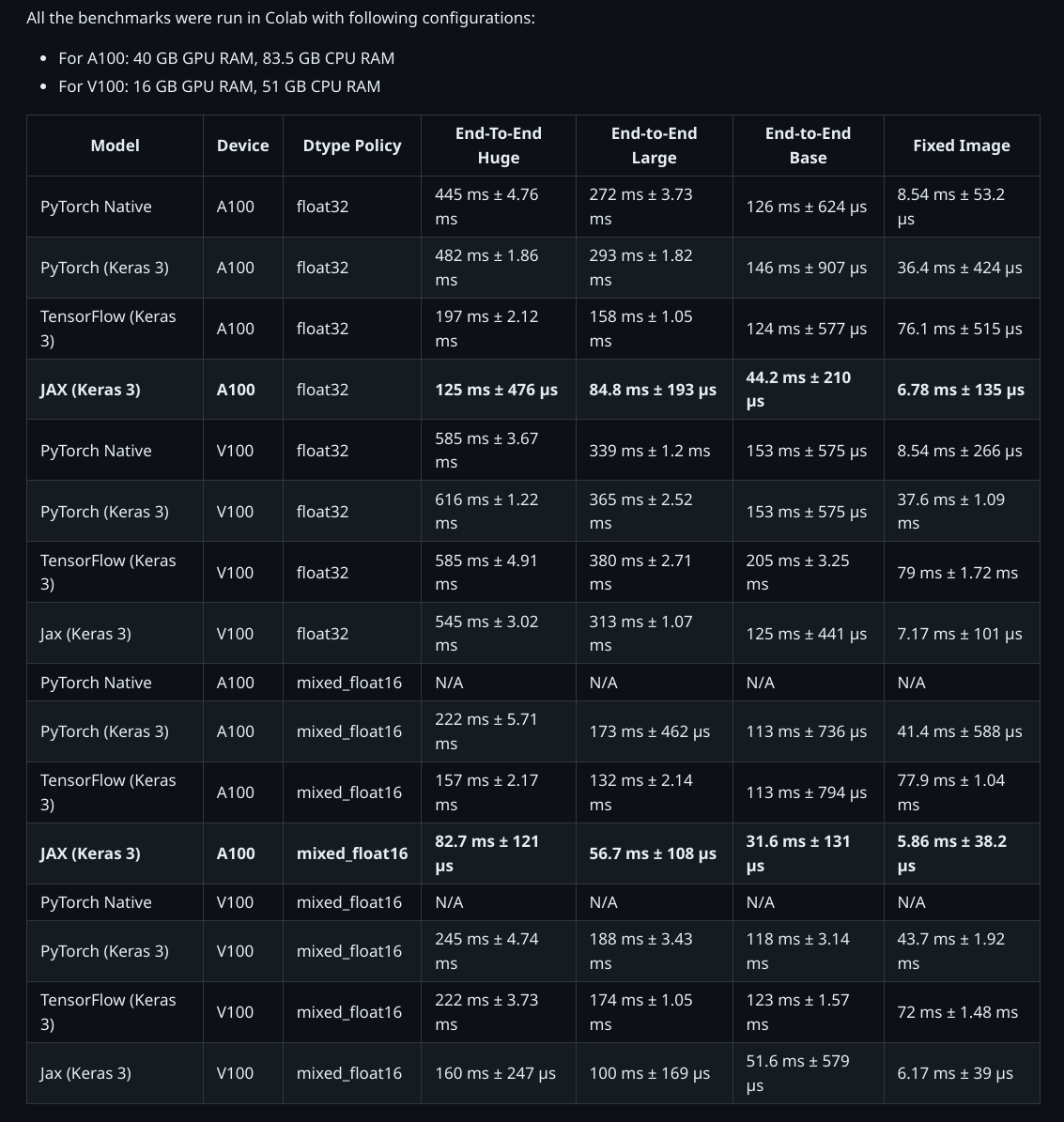
用於生成基準測試的腳本在此處提供。
結論
KerasHub 的 SegmentAnythingModel 支持各種應用程序,並且在 Keras 3 的幫助下,可以在 TensorFlow、JAX 和 PyTorch 上運行模型!借助 JAX 和 TensorFlow 中的 XLA,該模型的運行速度比原始實現快幾倍。此外,使用 Keras 的混合精度支持只需一行代碼即可幫助優化內存使用和計算時間!
有關更高級的用途,請查看自動遮罩生成器演示。