KerasHub 入門
作者: Matthew Watson、Jonathan Bischof
建立日期 2022/12/15
上次修改日期 2024/10/17
描述: KerasHub API 的簡介。

KerasHub 是一個預訓練模型函式庫,旨在簡單、彈性且快速。該函式庫提供熱門模型架構的 Keras 3 實作,並搭配可在 Kaggle 上取得的預訓練檢查點集合。模型可用於在 TensorFlow、Jax 和 Torch 後端上進行訓練和推論。
KerasHub 是核心 Keras API 的延伸;KerasHub 元件以 keras.Layer 和 keras.Model 的形式提供。如果您熟悉 Keras,恭喜!您已經了解 KerasHub 的大部分內容。
本指南旨在作為整個函式庫的入門介紹。我們將從使用高階 API 來分類影像和產生文字開始,然後逐步展示更深入的模型自訂和訓練。在整個指南中,我們使用 Keras 官方吉祥物 Professor Keras 作為材料複雜性的視覺參考。
與往常一樣,我們的 Keras 指南將專注於真實世界的程式碼範例。您可以隨時點擊指南頂部的 Colab 連結來試玩這裡的程式碼。
安裝與設定
首先,讓我們安裝 keras-hub。該函式庫可在 PyPI 上取得,因此我們可以使用 pip 簡單地安裝它。
!pip install --upgrade --quiet keras-hub-nightly keras-nightly
Keras 3 是建構在 TensorFlow、Jax 和 Torch 後端之上。在編寫 Keras 程式碼時,您應該在匯入任何函式庫之前先指定後端。我們將在本指南中使用 Jax 後端,但您可以使用 torch 或 tensorflow,而無需更改本指南其餘部分的任何一行。這就是 Keras 3 的強大之處!
我們還將設定 XLA_PYTHON_CLIENT_MEM_FRACTION,這會從一開始就釋放整個 GPU 供 Jax 使用。
import os
os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "1.0"
最後,我們需要進行一些額外的設定,才能存取本指南中使用的模型。許多熱門的開放式 LLM,例如 Google 的 Gemma 和 Meta 的 Llama,都需要先接受社群授權才能存取模型權重。我們將在本指南中使用 Gemma,因此我們可以按照以下步驟操作
- 前往 Gemma 2 模型頁面,並接受頂部橫幅中的授權。
- 前往 Kaggle 設定,並點擊「API」區段下的「建立新權杖」按鈕,以產生 Kaggle API 金鑰。
- 在您的 Colab 筆記本中,點擊左側工具列上的金鑰圖示。新增兩個機密:
KAGGLE_USERNAME,其中包含您的使用者名稱,以及KAGGLE_KEY,其中包含您剛建立的 API 金鑰。讓這些機密對您正在執行的筆記本可見。
API 快速入門
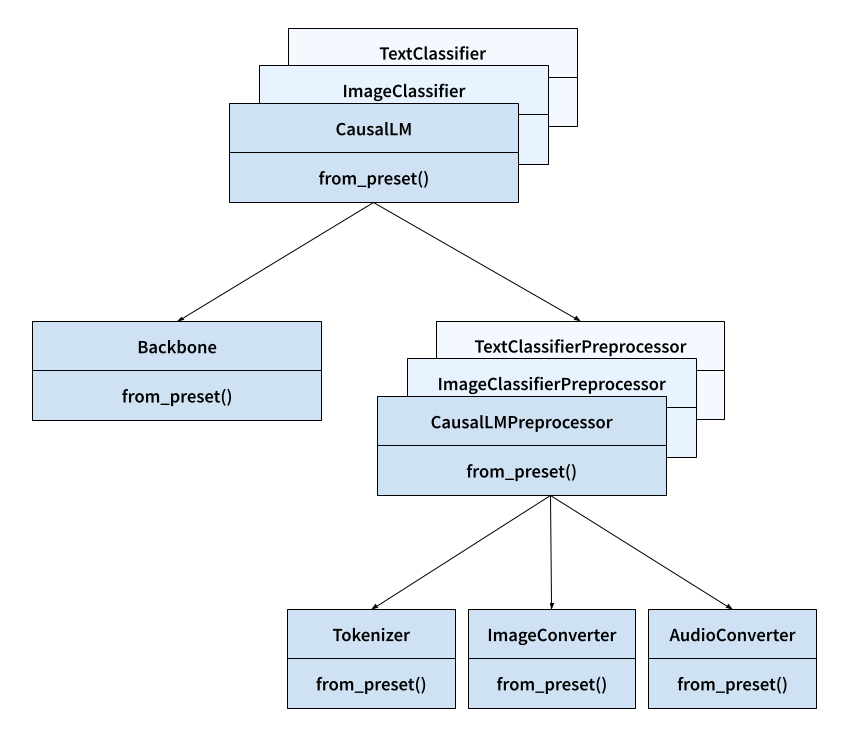
在開始之前,讓我們先看看我們將在 KerasHub 函式庫中使用的關鍵類別。
- 任務:例如,
keras_hub.models.CausalLM、keras_hub.models.ImageClassifier和keras_hub.models.TextClassifier。- 功能:任務會將原始影像、音訊和文字輸入對應到模型預測。
- 重要性:任務是 KerasHub API 的最高層級進入點。它將預處理和建模封裝到一個簡單易用的類別中。任務可用於微調和推論。
- 具有:
backbone和preprocessor。 - 繼承自:
keras.Model。
- 主幹:
keras_hub.models.Backbone。- 功能:將預處理的張量輸入對應到模型的潛在空間。
- 重要性:主幹以不專用於任何特定任務的方式封裝了預訓練模型的架構和參數。主幹可以與任意預處理和「標頭」層結合,將密集特徵對應到預測,以完成任何 ML 任務。
- 繼承自:
keras.Model。
- 預處理器:例如,
keras_hub.models.CausalLMPreprocessor、keras_hub.models.ImageClassifierPreprocessor和keras_hub.models.TextClassifierPreprocessor。- 功能:預處理器會將原始影像、音訊和文字輸入對應到預處理的張量輸入。
- 重要性:預處理層會封裝所有特定任務的預處理,例如影像大小調整和文字符號化,其使用方式可以獨立預先計算預處理的輸入。請注意,如果您使用的是高階任務類別,則預設已內建此預處理。
- 具有:
tokenizer、audio_converter和/或image_converter。 - 繼承自:
keras.layers.Layer。
- 符號化器:
keras_hub.tokenizers.Tokenizer。- 功能:將字串轉換為符號 ID 的序列。
- 重要性:字串的原始位元組是文字輸入的低效表示法,因此我們先將字串輸入對應到整數符號 ID。這個類別封裝了字串到整數的對應以及反向對應(透過
detokenize()方法)。 - 繼承自:
keras.layers.Layer。
- ImageConverter:
keras_hub.layers.ImageConverter。- 功能:調整影像輸入的大小和縮放。
- 重要性:影像模型通常需要將影像輸入正規化為特定範圍,或將輸入大小調整為特定大小。這個類別會封裝特定於影像的預處理。
- 繼承自:
keras.layers.Layer。
- AudioConveter:
keras_hub.layers.AudioConveter。- 功能:將原始音訊轉換為模型就緒的輸入。
- 重要性:音訊模型通常需要在將原始音訊輸入傳遞到模型之前對其進行預處理,例如計算音訊訊號的頻譜圖。這個類別會以易於使用的圖層封裝影像特定的預處理。
- 繼承自:
keras.layers.Layer。
這裡列出的所有類別都有 from_preset() 建構函式,它將使用給定預訓練模型識別碼的權重和狀態來執行個體化元件。例如,keras_hub.tokenizers.Tokenizer.from_preset("gemma2_2b_en") 將建立一個圖層,該圖層使用 Gemma2 符號化器詞彙表來符號化文字。
下圖顯示所有這些核心類別如何互動。箭頭表示組合而不是繼承(例如,任務具有主幹)。
分類影像

設定夠了!讓我們用預訓練模型來玩樂一下。讓我們載入加州鵪鶉的測試影像並將其分類。
import keras
import numpy as np
import matplotlib.pyplot as plt
image_url = "https://upload.wikimedia.org/wikipedia/commons/a/aa/California_quail.jpg"
image_path = keras.utils.get_file(origin=image_url)
image = keras.utils.load_img(image_path)
plt.imshow(image)

我們可以使用在 ImageNet-1k 資料庫上訓練的 ResNet 視覺模型。此模型將從 [0, 1000) 中提供每個輸入樣本和輸出標籤,其中每個標籤對應到一些真實世界的實體,例如「牛奶罐」或「豪豬」。資料集實際上在索引 85 處有一個鵪鶉的特定標籤。讓我們下載模型並預測標籤。
import keras_hub
image_classifier = keras_hub.models.ImageClassifier.from_preset(
"resnet_50_imagenet",
activation="softmax",
)
batch = np.array([image])
image_classifier.preprocessor.image_size = (224, 224)
preds = image_classifier.predict(batch)
preds.shape
1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step
(1, 1000)
這些 ImageNet 標籤不是特別「容易理解」,因此我們可以使用內建的實用函式將預測解碼為一組類別名稱。
keras_hub.utils.decode_imagenet_predictions(preds)
[[('quail', 0.9996534585952759),
('prairie_chicken', 8.45497488626279e-05),
('partridge', 1.4000976079842076e-05),
('black_grouse', 7.407367775158491e-06),
('bullet_train', 7.323932550207246e-06)]]
看起來不錯!模型權重已成功下載,並且我們幾乎肯定預測了鵪鶉影像的正確分類標籤。
這是我們在上述 API 快速入門中提到的高階任務 API 的第一個範例。 keras_hub.models.ImageClassifier 是一個用於分類影像的任務,並且可以與許多不同的模型架構(ResNet、VGG、MobileNet 等)一起使用。您可以在 Kaggle 上檢視 Keras 團隊直接提供的完整模型列表。
任務只是 keras.Model 的子類別 — 您可以像任何其他模型一樣在我們的 classifier 物件上使用 fit()、compile() 和 save()。但是,任務帶有一些由 KerasHub 函式庫提供的額外功能。第一個也是最重要的功能是 from_preset(),這是您將在 KerasHub 中的許多類別上看到的特殊建構函式。
預設是模型狀態的目錄。它定義我們應該載入的架構以及與之搭配使用的預訓練權重。 from_preset() 允許我們從許多不同的位置載入預設目錄
- 本機目錄。
- Kaggle 模型中心。
- HuggingFace 模型中心。
您可以查看 keras_hub.models.ImageClassifier.from_preset 文件,以更好地了解從預設建構 Keras 模型時的所有選項。
所有任務都使用兩個主要子物件。 keras_hub.models.Backbone 和 keras_hub.layers.Preprocessor。您可能已經熟悉電腦視覺中的主幹一詞,它通常用於描述將影像對應到潛在空間的特徵提取器網路。 KerasHub 主幹是此概念的概括,我們使用它來指代任何沒有特定任務標頭的預訓練模型。也就是說,KerasHub 主幹會將原始影像、音訊和文字(或這些輸入的組合)對應到預訓練模型的潛在空間。然後,我們可以將此潛在空間對應到任意數量的特定任務輸出,具體取決於我們嘗試對模型執行的操作。
預處理器只是一個 Keras 圖層,可為特定任務執行所有預處理。在我們的案例中,預處理會調整輸入影像的大小,並使用一些特定於 ImageNet 的平均值和變異數資料將其縮放到範圍 [0, 1]。讓我們依序呼叫任務的預處理器和主幹,看看我們的輸入形狀會發生什麼情況。
print("Raw input shape:", batch.shape)
resized_batch = image_classifier.preprocessor(batch)
print("Preprocessed input shape:", resized_batch.shape)
hidden_states = image_classifier.backbone(resized_batch)
print("Latent space shape:", hidden_states.shape)
Raw input shape: (1, 557, 707, 3)
Preprocessed input shape: (1, 224, 224, 3)
Latent space shape: (1, 7, 7, 2048)
我們的原始影像在預處理期間會縮放到 (224, 224),最後縮減為包含 2048 個特徵向量的 (7, 7) 影像 — ResNet 模型的潛在空間。請注意,ResNet 實際上可以處理任意大小的影像,但如果您的影像大小與預訓練資料差異很大,效能最終會下降。如果您想停用預處理層中的大小調整,您可以執行 image_classifier.preprocessor.image_size = None。
如果您想知道您載入的任務的確切結構,您可以像任何 Keras 模型一樣使用 model.summary()。任務的模型摘要將包含有關模型預處理的額外資訊。
image_classifier.summary()
Preprocessor: "res_net_image_classifier_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Config ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ res_net_image_converter │ Image size: (224, 224) │ │ (ResNetImageConverter) │ │ └──────────────────────────────────────────────┴───────────────────────────────┘
Model: "res_net_image_classifier"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, None, None, 3) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ res_net_backbone (ResNetBackbone) │ (None, None, None, 2048) │ 23,561,152 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ pooler (GlobalAveragePooling2D) │ (None, 2048) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ output_dropout (Dropout) │ (None, 2048) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ predictions (Dense) │ (None, 1000) │ 2,049,000 │ └───────────────────────────────────┴──────────────────────────┴───────────────┘
Total params: 25,610,152 (97.69 MB)
Trainable params: 25,557,032 (97.49 MB)
Non-trainable params: 53,120 (207.50 KB)
使用 LLM 產生文字

接下來,讓我們試著操作和產生文字。當產生文字時,我們可以使用的任務是 keras_hub.models.CausalLM (其中 LM 是 Language Model 的縮寫)。讓我們下載擁有 20 億參數的 Gemma 2 模型並試用看看。
由於這個模型比我們剛下載的 ResNet 模型大約 100 倍,我們需要更加注意 GPU 記憶體的使用。我們可以使用半精度類型來載入我們約 25 億的每個參數,將其儲存為 2 位元組的浮點數,而不是 4 位元組。為了做到這一點,我們可以將 dtype 傳遞給 from_preset() 建構子。 from_preset() 會將任何 kwargs 轉發到該類別的主要建構子,因此您可以傳遞適用於所有 Keras 層的 kwargs,例如 dtype、trainable 和 name。
causal_lm = keras_hub.models.CausalLM.from_preset(
"gemma2_instruct_2b_en",
dtype="bfloat16",
)
我們剛載入的模型是 Gemma 的指令微調版本,這表示該模型進一步針對聊天進行了微調。只要我們堅持使用訓練模型時使用的特定文字範本,我們就可以利用這些功能。這些特殊 token 會因模型而異,並且可能難以追蹤,Kaggle 模型頁面將包含此類詳細資訊。
CausalLM 帶有一個額外的函數 generate(),可以用於迴圈產生預測的 token,並將它們解碼為字串。
template = "<start_of_turn>user\n{question}<end_of_turn>\n<start_of_turn>model"
question = """Write a python program to generate the first 1000 prime numbers.
Just show the actual code."""
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Write a python program to generate the first 1000 prime numbers.
Just show the actual code.<end_of_turn>
<start_of_turn>model
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
count = 0
number = 2
primes = []
while count < 1000:
if is_prime(number):
primes.append(number)
count += 1
number += 1
print(primes)
<end_of_turn>
請注意,在 Jax 和 TensorFlow 後端,這個 generate() 函數會被編譯,因此第二次呼叫相同的 max_length 時,實際上會快得多。KerasHub 將使用 Jax 和 TensorFlow 來計算可重複使用的最佳化產生計算圖。
question = "Share a very simple brownie recipe."
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Share a very simple brownie recipe.<end_of_turn>
<start_of_turn>model
---
## Super Simple Brownies
**Ingredients:**
* 1 cup (2 sticks) unsalted butter, melted
* 2 cups granulated sugar
* 4 large eggs
* 1 teaspoon vanilla extract
* 1 cup all-purpose flour
* 1/2 cup unsweetened cocoa powder
* 1/4 teaspoon salt
**Instructions:**
1. Preheat oven to 350°F (175°C). Grease and flour a 9x13 inch baking pan.
2. In a large bowl, whisk together the melted butter and sugar until smooth.
3. Beat in the eggs one at a time, then stir in the vanilla extract.
4. In a separate bowl, whisk together the flour, cocoa powder, and salt.
5. Gradually add the dry ingredients to the wet ingredients, mixing until just combined. Do not overmix.
6. Pour the batter into the prepared pan and spread evenly.
7. Bake for 25-30 minutes, or until a toothpick inserted into the center comes out with a few moist crumbs attached.
8. Let cool completely before cutting and serving.
**Tips:**
* For extra fudgy brownies, underbake them slightly.
* Add chocolate chips, nuts, or other mix-ins to the batter for a personalized touch.
* Serve with a scoop of ice cream or whipped cream for a decadent treat.
Enjoy!
<end_of_turn>
與我們的圖像分類器一樣,我們可以利用模型摘要來查看我們任務設定的詳細資訊,包括預處理。
causal_lm.summary()
Preprocessor: "gemma_causal_lm_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Config ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gemma_tokenizer (GemmaTokenizer) │ Vocab size: 256,000 │ └──────────────────────────────────────────────┴───────────────────────────────┘
Model: "gemma_causal_lm"
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ gemma_backbone │ (None, None, │ 2,614,341,… │ padding_mask[0][0… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ token_embedding │ (None, None, │ 589,824,000 │ gemma_backbone[0]… │ │ (ReversibleEmbedding) │ 256000) │ │ │ └───────────────────────┴───────────────────┴─────────────┴────────────────────┘
Total params: 2,614,341,888 (4.87 GB)
Trainable params: 2,614,341,888 (4.87 GB)
Non-trainable params: 0 (0.00 B)
我們的文字預處理包含一個 token 化器,這是所有 KerasHub 模型處理輸入文字的方式。讓我們嘗試直接使用它,以更好地了解其運作方式。所有 token 化器都包含 tokenize() 和 detokenize() 方法,用於將字串對應到整數序列,以及將整數序列對應到字串。直接使用 tokenizer(inputs) 呼叫層等同於呼叫 tokenizer.tokenize(inputs)。
tokenizer = causal_lm.preprocessor.tokenizer
tokens_ids = tokenizer.tokenize("The quick brown fox jumps over the lazy dog.")
print(tokens_ids)
string = tokenizer.detokenize(tokens_ids)
print(string)
[ 651 4320 8426 25341 36271 1163 573 27894 5929 235265]
The quick brown fox jumps over the lazy dog.
CausalLM 模型的 generate() 函數涉及取樣步驟。對於我們想要產生的每個 token,都會呼叫一次 Gemma 模型,並傳回所有 token 的機率分佈。然後對此分佈進行取樣,以選擇序列中的下一個 token。
對於 Gemma 模型,我們預設使用貪婪取樣,這表示我們只是在每個步驟中選擇模型最有可能的輸出。但實際上,我們可以透過在所有 Keras 模型上的標準 compile 函數中新增一個 sampler 參數來控制此過程。讓我們試用看看。
causal_lm.compile(
sampler=keras_hub.samplers.TopKSampler(k=10, temperature=2.0),
)
question = "Share a very simple brownie recipe."
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Share a very simple brownie recipe.<end_of_turn>
<start_of_turn>model ## Ultimate Simple Brownies
This recipe requires NO oven or special equipment! Just microwave, mixing, and a few moments!
**Yields:** 6 large brownies
**Prep time:** 7 minutes
**Cook time:** 6-9 minutes, depending on your microwave
**What you need:**
* 3 ounces (about 2-3 tablespoons) chocolate chips
* 1/4 cup butter
* 1 large egg
* 1/2 cup granulated sugar
* 9 tablespoons all-purpose flour
**Optional Add-Ins (for extra fun):**
* 1/2 teaspoon vanilla
* 1/4 cup chopped walnuts or pecans
**Instructions:**
1. Place all microwave-safe mixing bowl ingredients:
- Chocolate Chips 🍫
- Butter 🧈
- Flour 🗲
- Egg (beaten!)
(You can add the optional add-INS like chopped nuts/extra vanilla, now is the good place to!)
2. Put all that in your microwave (microwave-safe dish or a heat-safe mug is fine!)
3. **Cook on:** Medium-high, stirring halfway.
* Time depends on your microwave, so keep checking, but aim for 6-9 minutes (if no stirring at least 8 mins). You want a thick, almost chewy-texture.
**To serve:** Cut up your brownies immediately and savor this classic treat. You'd also need a tall glass of cold milk or coffee (or both, if you've really enjoyed it).
Let me know if you want to experiment with a different chocolate or add-ins to make it even sweeter. Enjoy! 😉
<end_of_turn>
在這裡,我們使用了 Top-K 取樣器,這表示我們將隨機取樣由查看每個時間步驟中前 10 個預測 token 所形成的部分分佈。我們還傳遞了 temperature 值 2,這會在我們取樣之前將我們的預測分佈變平坦。
最終結果是,每次產生輸出時,我們都會更廣泛地探索我們模型的分佈。產生現在將成為一個隨機過程,每次我們重新執行產生時,都會得到不同的結果。我們可以注意到,結果感覺比貪婪搜尋「更鬆散」 — 更多的小錯誤、較不一致,以及將布朗尼放入微波爐的可疑建議。
您可以在 keras_hub.samplers 查看 Keras 支援的所有取樣器。
在跳到下一個章節之前,讓我們釋放大型 Gemma 模型佔用的記憶體。
del causal_lm
微調和發布圖像分類器

既然我們已經嘗試了執行圖像和文字的推論,現在讓我們嘗試執行訓練。我們將使用我們稍早的 ResNet 圖像分類器,並在簡單的貓與狗資料集上對其進行微調。我們可以先下載並解壓縮資料。
import pathlib
extract_dir = keras.utils.get_file(
"cats_vs_dogs",
"https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip",
extract=True,
)
data_dir = pathlib.Path(extract_dir) / "PetImages"
當處理大量真實世界的圖像資料時,損壞的圖像很常見。讓我們過濾掉標頭中沒有「JFIF」字串的編碼不良圖像。
num_skipped = 0
for path in data_dir.rglob("*.jpg"):
with open(path, "rb") as file:
is_jfif = b"JFIF" in file.peek(10)
if not is_jfif:
num_skipped += 1
os.remove(path)
print(f"Deleted {num_skipped} images.")
Deleted 1590 images.
我們可以利用 keras.utils.image_dataset_from_directory 載入資料集。這裡要注意的一個重要事項是,train_ds 和 val_ds 都會以 tf.data.Dataset 物件的形式傳回,包括在 torch 和 jax 後端。
KerasHub 將使用 tf.data 作為預設 API,在 CPU 上執行多執行緒預處理。tf.data 是一個強大的 API,用於訓練輸入管道,可以輕鬆擴展到複雜的多主機訓練作業。使用它不會限制您對後端的選擇,tf.data.Dataset 可以作為一般 numpy 資料的迭代器,並傳遞給任何 Keras 後端的 fit()。
train_ds, val_ds = keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="both",
seed=1337,
image_size=(256, 256),
batch_size=32,
)
Found 23410 files belonging to 2 classes.
Using 18728 files for training.
Using 4682 files for validation.
在最簡單的情況下,訓練我們的分類器可能只是簡單地使用我們的資料集呼叫模型的 fit()。但為了讓這個範例更有趣一點,讓我們展示如何在任務中自訂預處理。
在第一個範例中,我們看到了預設情況下,我們的 ResNet 模型的預處理如何調整大小和重新縮放我們的輸入。當我們建立模型時,可以自訂此預處理。我們可以使用 Keras 的影像預處理層來建立一個 keras.layers.Pipeline,它將重新縮放、隨機翻轉和隨機旋轉我們的輸入影像。這些隨機影像增強將使我們較小的資料集能夠作為較大、更多樣的資料集運作。讓我們試用看看。
preprocessor = keras.layers.Pipeline(
[
keras.layers.Rescaling(1.0 / 255),
keras.layers.RandomFlip("horizontal"),
keras.layers.RandomRotation(0.2),
]
)
現在我們已經建立了一個新的預處理層,我們可以在 from_preset() 建構子期間將其傳遞給 ImageClassifier。我們也可以傳遞 num_classes=2 以符合我們「貓」和「狗」的兩個標籤。當像這樣指定 num_classes 時,我們模型的頭部權重將會隨機初始化,而不是包含我們 1000 類影像分類的權重。
image_classifier = keras_hub.models.ImageClassifier.from_preset(
"resnet_50_imagenet",
activation="softmax",
num_classes=2,
preprocessor=preprocessor,
)
請注意,如果您想在 Keras 之外預處理您的輸入資料,您可以簡單地將 preprocessor=None 傳遞給任務的 from_preset() 呼叫。在這種情況下,KerasHub 將完全不套用預處理,您可以自由地使用任何函式庫或工作流程來預處理您的資料,然後再將資料傳遞給 fit()。
接下來,我們可以編譯我們的模型以進行微調。KerasHub 任務只是一個具有某些額外功能的常規 keras.Model,因此我們可以像往常一樣針對分類任務進行 compile()。
image_classifier.compile(
optimizer=keras.optimizers.Adam(1e-4),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
有了這些,我們就可以簡單地執行 fit()。圖像分類器將在訓練模型時自動將我們的預處理套用至每個批次。
image_classifier.fit(
train_ds,
validation_data=val_ds,
epochs=3,
)
Epoch 1/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 0s 122ms/step - accuracy: 0.8869 - loss: 0.2921
Epoch 2/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 65s 105ms/step - accuracy: 0.9858 - loss: 0.0393 - val_accuracy: 0.9912 - val_loss: 0.0234
Epoch 3/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 57s 96ms/step - accuracy: 0.9897 - loss: 0.0289 - val_accuracy: 0.9930 - val_loss: 0.0206
<keras.src.callbacks.history.History at 0x787e77fb2550>
經過三個時期的資料後,我們在貓與狗驗證資料集上達到了 99% 的準確度。這並不奇怪,因為我們開始使用的 ImageNet 預訓練權重已經可以單獨分類一些品種的貓和狗。
現在我們有一個微調的模型,讓我們嘗試儲存它。您可以透過簡單地執行 task.save_to_preset() 來為任何任務建立具有微調模型的新儲存預設。
image_classifier.save_to_preset("cats_vs_dogs")
KerasHub 最強大的功能之一是能夠將模型上傳到 Kaggle 或 Huggingface 模型中心並與他人分享。 keras_hub.upload_preset 允許您上傳儲存的預設。
在這種情況下,我們將上傳到 Kaggle。我們已經與 Kaggle 進行了身分驗證,以便稍早下載 Gemma 模型。執行下列儲存格,以將新模型上傳到 Kaggle。
from google.colab import userdata
username = userdata.get("KAGGLE_USERNAME")
keras_hub.upload_preset(
f"kaggle://{username}/resnet/keras/cats_vs_dogs",
"cats_vs_dogs",
)
Uploading Model https://www.kaggle.com/models/matthewdwatson/resnet/keras/cats_vs_dogs ...
Upload successful: cats_vs_dogs/task.json (5KB)
Upload successful: cats_vs_dogs/task.weights.h5 (270MB)
Upload successful: cats_vs_dogs/metadata.json (157B)
Upload successful: cats_vs_dogs/model.weights.h5 (90MB)
Upload successful: cats_vs_dogs/config.json (841B)
Upload successful: cats_vs_dogs/preprocessor.json (3KB)
Your model instance version has been created.
Files are being processed...
See at: https://www.kaggle.com/models/matthewdwatson/resnet/keras/cats_vs_dogs
讓我們看一下我們資料集中的測試影像。
image = keras.utils.load_img(data_dir / "Cat" / "6779.jpg")
plt.imshow(image)

如果我們等待幾分鐘,讓我們的模型上傳在 Kaggle 端完成處理,我們可以繼續下載我們剛建立的模型,並用它來分類此測試影像。
image_classifier = keras_hub.models.ImageClassifier.from_preset(
f"kaggle://{username}/resnet/keras/cats_vs_dogs",
)
print(image_classifier.predict(np.array([image])))
1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step
[[9.999286e-01 7.135461e-05]]
恭喜您使用 KerasHub 上傳了您的第一個模型!如果您想與他人分享您的作品,您可以前往我們上傳模型時列印的模型連結,並在設定中將模型設為公開。
讓我們刪除此模型以釋放記憶體,然後再繼續本指南的最後一個範例。
del image_classifier
建立自訂文字分類器

作為本入門指南的最後一個範例,讓我們看看如何從較低層級的 Keras 和 KerasHub 元件建置自訂模型。我們將建立一個文字分類器,以將 IMDb 資料集中的電影評論分類為正面或負面。
讓我們下載資料集。
extract_dir = keras.utils.get_file(
"imdb_reviews",
origin="https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True,
)
data_dir = pathlib.Path(extract_dir) / "aclImdb"
IMDb 資料集包含大量未標記的電影評論。我們這裡不需要這些,我們可以簡單地刪除它們。
import shutil
shutil.rmtree(data_dir / "train" / "unsup")
接下來,我們可以使用 keras.utils.text_dataset_from_directory 載入我們的資料。與我們上面的影像資料集建立一樣,傳回的資料集將會是 tf.data.Dataset 物件。
raw_train_ds = keras.utils.text_dataset_from_directory(
data_dir / "train",
batch_size=2,
)
raw_val_ds = keras.utils.text_dataset_from_directory(
data_dir / "test",
batch_size=2,
)
Found 25000 files belonging to 2 classes.
Found 25000 files belonging to 2 classes.
KerasHub 的設計是分層的 API。在最上層,任務旨在讓您輕鬆快速地解決問題。我們可以在這裡繼續使用任務 API,並為文字分類模型(例如 BERT)建立一個 keras_hub.models.TextClassifer,並在大約 10 行程式碼中對其進行微調。
相反,為了使我們的最後一個範例更有趣一點,讓我們展示如何使用較低層級的 API 元件來執行該函式庫中沒有直接內建的功能。我們將使用我們稍早使用的 Gemma 2 模型(通常用於產生文字),並修改它以輸出分類預測。
使用生成模型進行分類的常見方法是讓它繼續在生成環境中使用,方法是提示它評論和一個問題("此評論是正面還是負面?")。但是,如果您想要與標籤相關聯的實際機率分數,則建立實際的分類器會更有用。
我們可以不透過 CausalLM 任務載入 Gemma 2 模型,而是載入兩個較低層級的元件:一個主幹和一個 token 化器。就像我們到目前為止使用的任務類別一樣,keras_hub.models.Backbone 和 keras_hub.tokenizers.Tokenizer 都有一個 from_preset() 建構子,用於載入預先訓練的模型。如果您正在執行此程式碼,您會注意到您不必等待下載,因為我們第二次使用模型,權重檔案會在我們第一次使用模型時在本機快取。
tokenizer = keras_hub.tokenizers.Tokenizer.from_preset(
"gemma2_instruct_2b_en",
)
backbone = keras_hub.models.Backbone.from_preset(
"gemma2_instruct_2b_en",
)
我們在本指南的第二個範例中看到了 token 化器的工作原理。我們可以利用它以符合 Gemma 模型預先訓練權重的方式,將字串輸入對應到 token ID。
主幹會將一連串 token ID 對應到模型潛在空間中嵌入的 token 序列。我們可以使用這個豐富的表示來建立分類器。
讓我們先定義一個自訂的預處理常式。keras_hub.layers 包含一系列建模和預處理層,其中包括一些用於詞元預處理的層。我們可以利用 keras_hub.layers.StartEndPacker,它會在每個評論的開頭附加一個特殊的起始詞元,在結尾附加一個特殊的結束詞元,最後將每個評論截斷或填充到固定長度。
如果將這個與我們的 tokenizer 結合使用,我們可以建立一個預處理函數,它將輸出形狀為 (batch_size, sequence_length) 的詞元 ID 批次。我們還應該輸出一個填充遮罩,標記哪些詞元是填充詞元,這樣我們稍後就可以在 Transformer 的注意力計算中排除這些位置。KerasNLP 中的大多數 Transformer 主幹都會接收一個 "padding_mask" 輸入。
packer = keras_hub.layers.StartEndPacker(
start_value=tokenizer.start_token_id,
end_value=tokenizer.end_token_id,
pad_value=tokenizer.pad_token_id,
sequence_length=None,
)
def preprocess(x, y=None, sequence_length=256):
x = tokenizer(x)
x = packer(x, sequence_length=sequence_length)
x = {
"token_ids": x,
"padding_mask": x != tokenizer.pad_token_id,
}
return keras.utils.pack_x_y_sample_weight(x, y)
定義好預處理後,我們可以簡單地使用 tf.data.Dataset.map 將預處理應用於我們的輸入數據。
train_ds = raw_train_ds.map(preprocess, num_parallel_calls=16)
val_ds = raw_val_ds.map(preprocess, num_parallel_calls=16)
next(iter(train_ds))
({'token_ids': <tf.Tensor: shape=(2, 256), dtype=int32, numpy=
array([[ 2, 94300, 1185, ... 0]],
dtype=int32)>,
'padding_mask': <tf.Tensor: shape=(2, 256), dtype=bool, numpy=
array([[ True, True, True, ... False]])>},
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 0], dtype=int32)>)
與我們之前訓練的圖像分類器相比,在 25 億參數模型上運行微調相當昂貴,原因很簡單,因為這個模型的大小是 ResNet 的 100 倍!為了加快速度,讓我們將訓練數據的大小縮減到原始大小的十分之一。當然,與完整訓練相比,這會犧牲一些效能,但它可以讓我們的指南運行得更快。
train_ds = train_ds.take(1000)
val_ds = val_ds.take(1000)
接下來,我們需要將分類頭附加到我們的主幹模型。一般來說,文字 Transformer 主幹會輸出一個形狀為 (batch_size, sequence_length, hidden_dim) 的張量。我們需要用這個輸入進行分類的主要事情是對序列維度進行池化,以便每個輸入範例都有一個單一的特徵向量。
由於 Gemma 模型是一個生成模型,資訊只會從序列的左側傳遞到右側。唯一可以「看到」完整電影評論輸入的詞元表示是每個評論中的最後一個詞元。我們可以編寫一個簡單的池化層來做到這一點 — 我們只會獲取每個輸入序列的最後一個非填充位置。編寫這樣的層沒有什麼特殊流程,我們可以像平常一樣使用 Keras 和 keras.ops。
from keras import ops
class LastTokenPooler(keras.layers.Layer):
def call(self, inputs, padding_mask):
end_positions = ops.sum(padding_mask, axis=1, keepdims=True) - 1
end_positions = ops.cast(end_positions, "int")[:, :, None]
outputs = ops.take_along_axis(inputs, end_positions, axis=1)
return ops.squeeze(outputs, axis=1)
有了這個池化層,我們就可以編寫我們的 Gemma 分類器了。KerasHub 中的所有任務和主幹模型都是 函數式 模型,因此我們可以輕鬆地操作模型結構。我們將在我們的輸入上呼叫我們的主幹,加入我們新的池化層,最後加入一個中間帶有 "relu" 激活的小型前饋網路。讓我們試試看。
inputs = backbone.input
x = backbone(inputs)
x = LastTokenPooler(
name="pooler",
)(x, inputs["padding_mask"])
x = keras.layers.Dense(
2048,
activation="relu",
name="pooled_dense",
)(x)
x = keras.layers.Dropout(
0.1,
name="output_dropout",
)(x)
outputs = keras.layers.Dense(
2,
activation="softmax",
name="output_dense",
)(x)
text_classifier = keras.Model(inputs, outputs)
text_classifier.summary()
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ gemma_backbone │ (None, None, │ 2,614,341… │ padding_mask[0][… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooler │ (None, 2304) │ 0 │ gemma_backbone[0… │ │ (LastTokenPooler) │ │ │ padding_mask[0][… │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooled_dense │ (None, 2048) │ 4,720,640 │ pooler[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dropout │ (None, 2048) │ 0 │ pooled_dense[0][… │ │ (Dropout) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dense │ (None, 2) │ 4,098 │ output_dropout[0… │ │ (Dense) │ │ │ │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 2,619,066,626 (9.76 GB)
Trainable params: 2,619,066,626 (9.76 GB)
Non-trainable params: 0 (0.00 B)
在我們訓練之前,還有最後一個技巧我們應該使用,以使此程式碼在免費級別的 Colab GPU 上運行。從我們的模型摘要中可以看到,我們的模型佔用了將近 10 GB 的空間。最佳化器需要在訓練期間建立每個參數的多個副本,使得我們模型在訓練期間的總空間接近 30 或 40 GB。
這會導致許多 GPU 記憶體不足 (OOM)。我們可以採用一個有用的技巧,就是在我們的主幹上啟用 LoRA。LoRA 是一種凍結整個模型的方法,只訓練大型權重矩陣的低參數分解。您可以在這個 Keras 範例中閱讀更多關於 LoRA 的資訊。讓我們嘗試啟用它並重新印出我們的摘要。
backbone.enable_lora(4)
text_classifier.summary()
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ gemma_backbone │ (None, None, │ 2,617,270… │ padding_mask[0][… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooler │ (None, 2304) │ 0 │ gemma_backbone[0… │ │ (LastTokenPooler) │ │ │ padding_mask[0][… │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooled_dense │ (None, 2048) │ 4,720,640 │ pooler[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dropout │ (None, 2048) │ 0 │ pooled_dense[0][… │ │ (Dropout) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dense │ (None, 2) │ 4,098 │ output_dropout[0… │ │ (Dense) │ │ │ │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 2,621,995,266 (9.77 GB)
Trainable params: 7,653,378 (29.20 MB)
Non-trainable params: 2,614,341,888 (9.74 GB)
啟用 LoRA 後,我們的模型從 10 GB 的可訓練參數減少到僅 20 MB。這表示最佳化器變數所使用的空間不再是問題。
完成所有設定後,我們可以像平常一樣編譯和訓練我們的模型。
text_classifier.compile(
optimizer=keras.optimizers.Adam(5e-5),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
text_classifier.fit(
train_ds,
validation_data=val_ds,
)
1000/1000 ━━━━━━━━━━━━━━━━━━━━ 295s 285ms/step - accuracy: 0.7733 - loss: 0.6511 - val_accuracy: 0.9370 - val_loss: 0.2814
<keras.src.callbacks.history.History at 0x787e103ae010>
我們能夠在電影評論情感分類問題上達到超過 ~93% 的準確度。這還不錯,因為我們只使用了原始資料集的十分之一進行訓練。
總而言之,我們在這個範例中建立的 backbone 和 tokenizer 讓我們可以存取預訓練 Gemma 檢查點的全部功能,而不會限制我們可以使用它們做什麼。這是 KerasHub API 的主要目標。簡單的工作流程應該很容易,而且隨著您的深入,您可以存取一組高度可自訂的建構區塊。
進一步探索
這只是 KerasHub 功能的冰山一角。
本指南展示了一些我們隨 KerasHub 程式庫提供的進階任務,但還有許多我們未涵蓋的任務。例如,嘗試使用 Stable Diffusion 生成圖像。
KerasHub 最顯著的優勢在於,它讓您可以靈活地將預訓練的建構區塊與 Keras 3 的全部功能結合使用。您可以使用 keras.distribution API 在 TPU 上以模型平行方式訓練大型 LLM。您可以使用 Keras 的量化方法來量化模型。您可以編寫自訂訓練迴圈,甚至可以混合使用直接 Jax、Torch 或 TensorFlow 呼叫。
請參閱 keras.io/keras_hub,以取得完整指南和範例列表,以繼續深入研究程式庫。